Architecture
Terraform Enterprise automates infrastructure provisioning and lifecycle management. It also integrates with the ecosystem to offer additional features like single sign-on for user authentication, version control, observability, and artifact management.
Design attributes
Most decision points in this document require the evaluation of non-functional requirements to find a recommendation that is acceptable within the bounds of a typical customer environment. Where possible, decisions accompany associated narrative allowing the reader to understand our rationale.
- Availability: Represents design points that minimize the impact of subsystem failures on the solution uptime. An example of this is introducing multiple load-balanced application instances.
- Operational complexity: From time to time, it is necessary to introduce some complexity during the initial deployment to provide a reduced effort for operations teams to manage the solution. An example of this is introducing a machine imaging process with Packer that permits immutable operations for scaling up/down and application updates.
- Scalability: Some design choices may work at a small scale but introduce overhead as the solution scales. An example of this is choosing to onboard teams using a manual process in the Terraform Enterprise UI rather than creating an automated onboarding workflow to complete the necessary setup.
- Security: Indicates how a decision changes the security posture of the overall solution. An example of this is taking advantage of workload identity so that workspaces authenticate against their API targets using JWT based workflows rather than using long-lived credentials as workspace variables.
Terraform Enterprise components
Terraform Enterprise consists of several components, each with specific responsibilities in the overall architecture. This section explains the function of each component and the technologies they support.
- Terraform Enterprise application: This is the Terraform Enterprise container that HashiCorp provides as the core application. See the Terraform HVD Module code for the latest default machine size or type for the respective cloud or Kubernetes environment. These link from the Deployment pages later in this HVD.
- HCP Terraform agent (optional): A fleet of isolated execution environments that perform Terraform runs on behalf of Terraform Enterprise users. The HCP Terraform agent (which is also usable with Terraform Enterprise) can consume APIs in isolated network segments to provide quality of service to specific teams in your organization or distributes load away from the core Terraform Enterprise service. While use of HCP Terraform agents is highly recommended, it is not required. Terraform Enterprise comes with built-in agents for job execution.
- PostgreSQL database: Serves as the primary store of Terraform Enterprise's application data such as workspace settings and user settings. You can review the supported versions and requirements on our Terraform Enterprise PostgreSQL(opens in new tab) page.
- Redis cache: Used for caching and coordination between Terraform Enterprise core's web and background workers. In order to have multiple, simultaneously active application nodes, you require an external cache. We have validated Terraform Enterprise with the native Redis services from AWS, Azure, and GCP. Terraform Enterprise uses Redis internally on single-node VMware-based deployments. You can review the supported versions and requirements on our Terraform Enterprise Redis(opens in new tab) page.
- Object Storage: Used for storage of Terraform state files, plan files, configuration, output logs and other such objects. All objects persisted to blob storage are symmetrically encrypted then written. A unique encryption key encrypts each object using 128 bit AES in CTR mode. The internal HashiCorp Vault transit secret engine processes the key material, which stores the default transit encryption cipher (AES-GCM with a 256-bit AES key and a 96-bit nonce), alongside the object. This pattern is envelope encryption. Any S3-compatible object storage service, GCP Cloud Storage or Azure blob storage meets Terraform Enterprise's object storage requirements. You must create an object store instance for Terraform Enterprise to use, and specify its connection string details during installation. We recommend you ensure the object store is in the same region as the Terraform Enterprise instance.
Operational modes
In this section, we review the supported operational modes for Terraform Enterprise.
From v202309-1(opens in new tab), Terraform Enterprise is compatible with a variety of platforms including Kubernetes. Our official installation documentation for this is here(opens in new tab). We recommend using this for all private cloud deployments.
| Operational mode | Characteristics | Description |
|---|---|---|
disk | All Terraform Enterprise services deploy onto a single node. | Most suitable for functional testing, training, and gaining familiarity. Do not use for production. |
external | External database, external object storage, stateless application installed on a single node with internal cache with optional, remote Terraform agents. | Most suitable for organizations who focus on system performance, but less so with system resilience. |
active-active | Replicated database and object storage, external caching layer and multiple, stateless application nodes in redundant availability zones. Optionally, multiple remote Terraform agents. | Most suitable for a business-wide service that requires the highest levels of resilience and performance. |
disk mode
In a disk mode deployment, an organization deploys Terraform Enterprise in a singular compute environment without failover or active/active capabilities. In this deployment model, all services (including PostgreSQL DB and other storage requirements) are self-contained within the Docker environment, eliminating external dependencies. The application data is self-managed and uses localized Docker disk volumes for caching and data operations.
A disk deployment is well-suited for development, functional testing, and acceptance testing scenarios, however we do not recommend that you use this for any production environments. For production deployments, use only the external or active-active operational modes.
The following diagram illustrates the logical architecture of a disk Terraform Enterprise deployment:
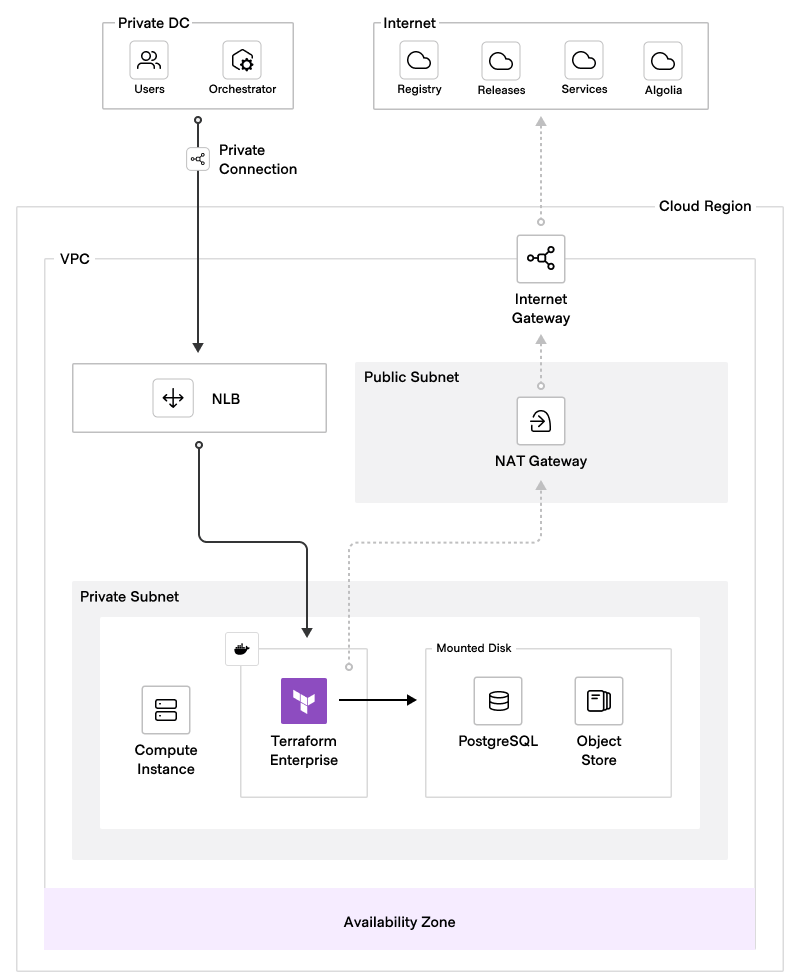
The benefits of this deployment model include minimal resource requirements, reduced reliance on specialized expertise, and rapid deployment. However, it lacks enterprise-grade resiliency for unexpected downtime and cannot scale performance without interrupting services.
external mode
To move to a stateless application front-end, the external operational mode takes the application database and object storage and moves them to dedicated infrastructure. The cache remains internal but represents transient caching only.
Each of the public clouds provides native services for a PostgreSQL database and object storage that supports this deployment pattern. The configuration of these external services decouples the application infrastructure, eliminating single points of vulnerability and improving availability. While this deployment model may not offer performance scalability (although AWS Aurora storage scales and minimizing downtime is possible when scaling the DB instance through instance failover), it enhances the deployment resilience by distributing the core components.
The model is an initial step towards a fully resilient and scalable deployment. It relies on one compute environment for a Docker engine. This means that this single instance of the Terraform Enterprise application becomes a vulnerable single point of failure for an enterprise-grade operation. If your target architecture requires zero downtime from expected failures such as instance or availability zone failure, we recommend active-active below.
active-active mode (multiple compute instances)
When your organization requires increased availability or performance from Terraform Enterprise that your current single application instance cannot provide, it is time to scale to the active-active operational mode.
Before scaling to this mode, weigh its benefits against the increased operational complexity. Specifically, consider the following aspects.
- An automated Terraform Enterprise deployment process is a hard requirement
- When monitoring multiple Terraform Enterprise instances, it is important to consider the impact on your monitoring dashboards and alerts.
- To effectively manage the lifecycle of application nodes, custom automation is necessary.
Terraform Enterprise supports active-active mode, which involves combining multiple instances of Terraform Enterprise with external services. In this model, separate Docker engines (on VMs, or by an orchestrator such as Kubernetes) host the primary application services, spread across at least three availability zones within the same cloud region. These instances connect to centralized services that provide the application database, shared object storage and durable cache, all managed by the cloud service provider.
Using an active/active model has a key advantage: It eliminates potential service failure points. By distributing multiple application instances, the service becomes more resilient and available. The deployment includes redundant elements that improve reliability, increase resilience, and enhance performance.
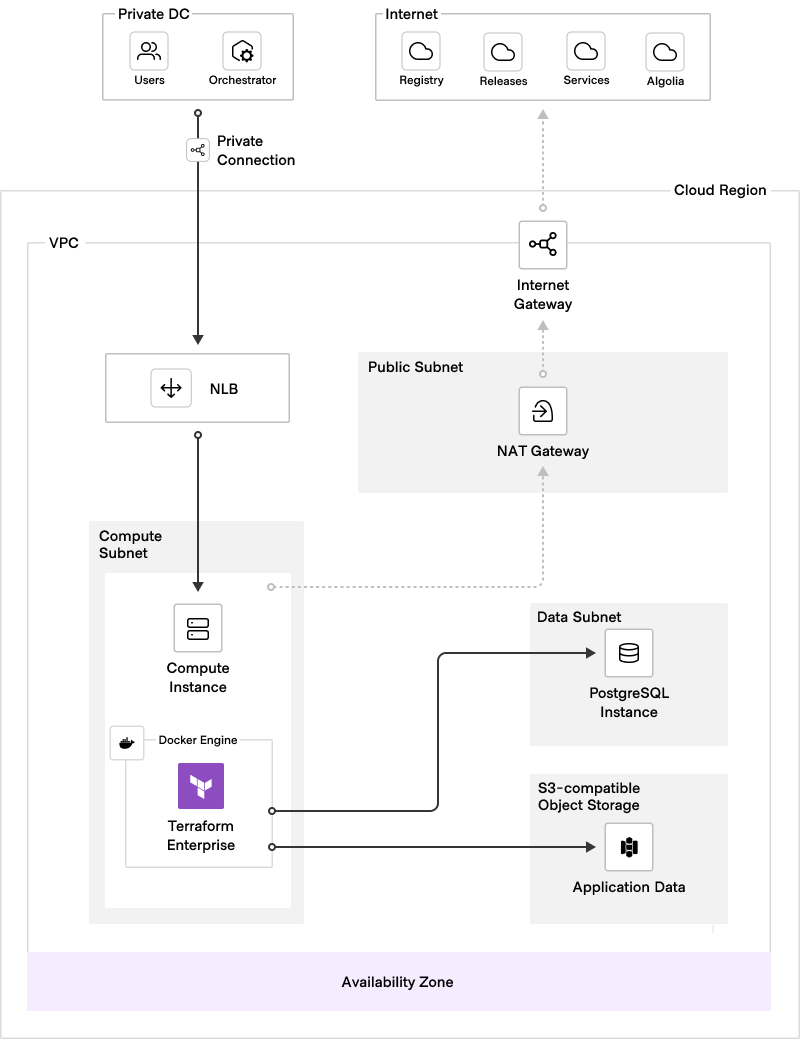
The following diagram illustrates the recommended architecture for an active-active mode deployment. It provides a visual representation of data flow, user access, key connections, and infrastructure components.

In addition to improved availability, active-active mode offers scalability and supportability benefits. The presence of multiple application instances allows for better workload distribution, alleviating bottlenecks and enhancing overall performance, with redundant application instances and external services.
Operational mode decision
The active-active mode topology offers crucial benefits to your organization and is our recommendation because it:
- Ensures service availability and scalability while mitigating potential failure scenarios caused by service interruption or resource starvation.
- Safeguards against revenue loss due to unscheduled service interruptions.
- Ensures data integrity while adhering to your data residency security guidelines.
Automated versus manual installation
As mentioned, customers deploying Terraform Enterprise using active-active mode must use automated means, and this requirement must guide your thoughts as to how this needs to occur with your installation approach.
For public cloud customers, we recommend our Terraform-based HVD Modules and external or active-active modes on VM-based deployments, and for EKS, AKS and GKE use only active-active mode. If you are a public cloud customer intending to deploy disk mode for development and testing, develop an automated deployment which works for you, to be able to destroy and recreate instances iteratively for which we recommend Packer(opens in new tab).
For private cloud customers who have Chef, Puppet, Ansible, Salt or other automated configuration management technologies as their organisational standard, we agree that use of such is the best practice because it provides
- A well-known approach to installation and software management for your organization and thus
- Lower barrier to success in deployment.
- Adherence to organizational standard likely also means increased chance of regulatory compliance where applicable.
We advise private cloud customers to automate deployment of Terraform Enterprise irrespective of the operational mode used because
- If you decide to manually install Terraform Enterprise, this increases the length of time and the amount of human involvement required to upgrade each instance each month. Automation reduces this burden.
- Automated installation means being able to version and collaborate on code used.
- Automated installation also means being able to rely on the same deployment pattern every time, which increases maintenance confidence for both architecture teams and services teams responsible for managing the product in production.