Architecture
In this section, we will explore the architecture of the HashiCorp Validated Design for Nomad Enterprise. This architecture is designed to provide a highly-available, scalable, and secure Nomad Enterprise deployment that is suitable for production workloads, and is intended to be used as a starting point for your own Nomad Enterprise deployments. First, we will discuss the components that make up a single Nomad cluster and its related infrastructure. We will then add a secondary Nomad cluster, culminating in a multi-cluster architecture.
The primary components that make up a single Nomad cluster are:
- Cluster of Nomad servers
- Load balancer
- Snapshot Storage (Backups)
- Nomad clients
Cluster
Nomad uses a server/client architecture. Nomad servers are hosting HTTP(S), Serf and RPC endpoints. Throught these endpoints, operators and Nomad clients can communicate with the Nomad servers.
The Nomad servers are responsible for scheduling and managing jobs, while the Nomad clients are responsible for executing the tasks that make up those jobs.
Clustering
Nomad multi-node deployment is designed for high-availability. This protects against outages by configuring multiple Nomad servers to operate as a single Nomad cluster. To ensure this high-availability, nodes within a cluster should always be spread across multiple availability zones.
The cluster is bootstrapped during the initialization process. Initial bootstrapping results in a cluster of desired count(opens in new tab) of nodes. One of the nodes is being elected as the leader, while the other nodes accept the role of the followers). Once a follower node has successfully joined the cluster, data from the leader will begin to replicate to it.
In a Nomad cluster, only the leader performs the scheduling. Follower nodes can perform reads against storage and forward writes to the leader node.
A Nomad cluster must maintain quorum in order to continue servicing requests. Because of this, nodes should be spread across availability zones to increase fault tolerance.
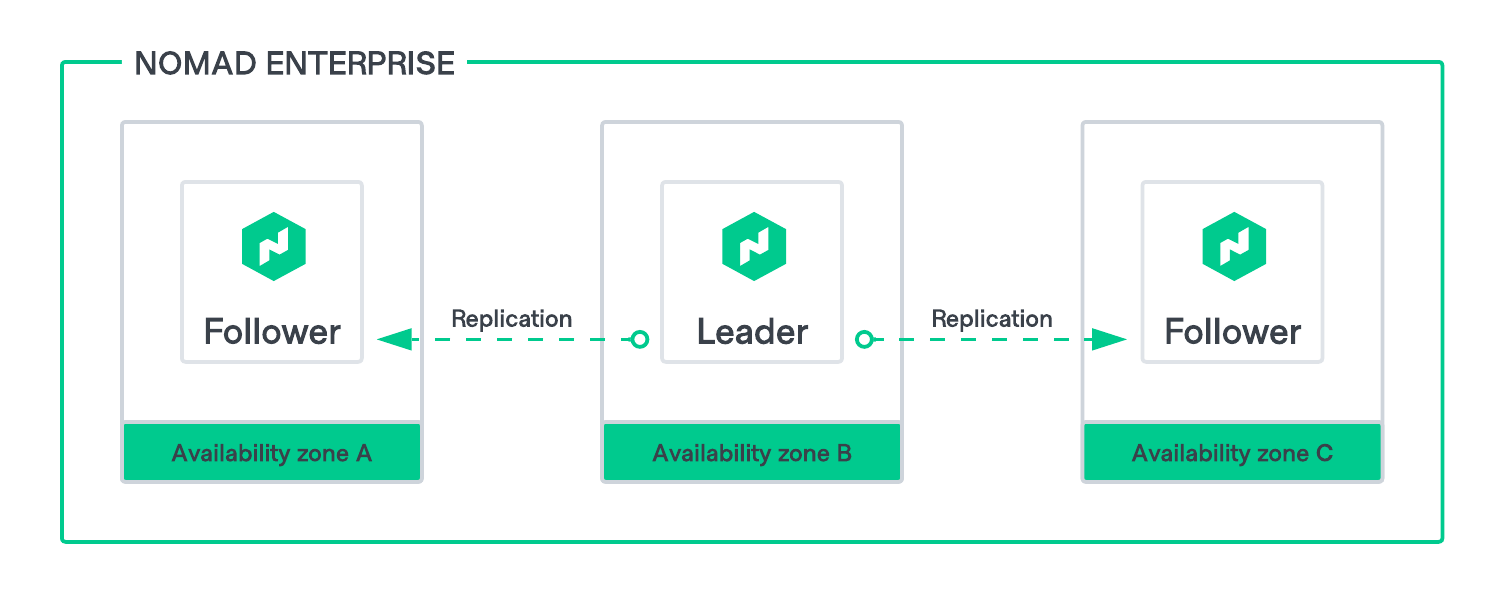 Figure 1: HVD Nomad HA 3 nodes diagram
Figure 1: HVD Nomad HA 3 nodes diagram
Voting nodes vs non-voting nodes
By default, standby nodes are also voters. If the active node becomes unavailable, a new active node is chosen by and among the remaining standby nodes. However, standby nodes can also be specified as non-voters.
Non-voting nodes also act as data replication targets, but do not contribute to the quorum count.
Autopilot
A non-voting node can be be promoted to a voting node through the use of Nomad Enterprise's Autopilot(opens in new tab) functionality. In addition to this, Autopilot also enables several automated workflows for managing Nomad clusters, including Server Stabilization, Automated Upgrades, and Redundancy Zones.
For more information, see the HashiCorp Documentation on Nomad Enterprise Autopilot(opens in new tab).
Redundancy zones
Using Nomad Enterprise Redundancy Zones(opens in new tab), Nomad cluster leverages a pair of nodes in each availability zone, with one node configured as a voter and the other as a non-voter. If one voter becomes unavailable (regardless of whether it is an active node or a standby node), Autopilot will promote its non-voting partner to take its place as a voter.
This architecture gives high availability both within an availability zone as well as across availability zones, ensuring that (n+1)/2 redundancy is maintained at all times.
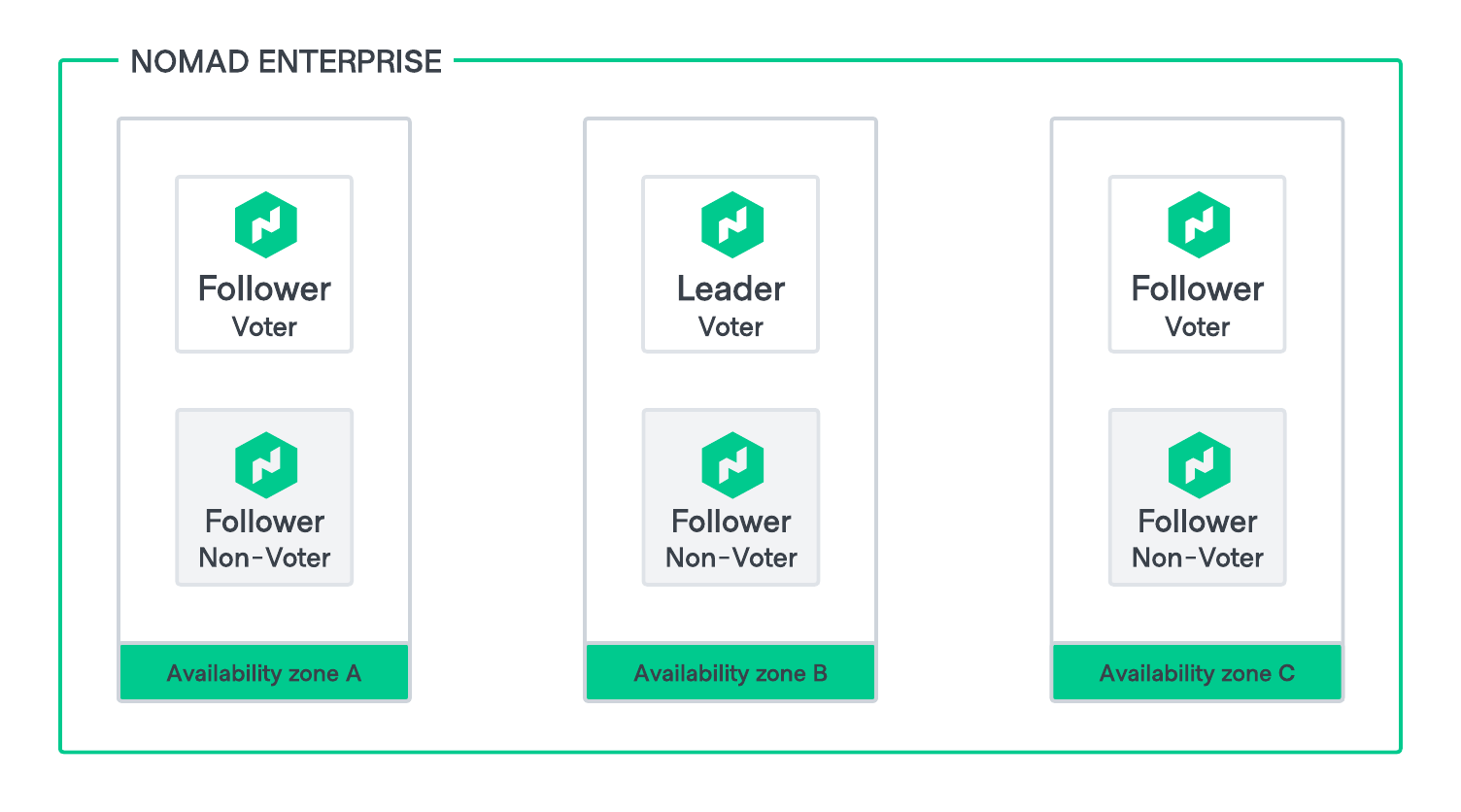 Figure 2: HVD Nomad HA 6 nodes redundancy zones diagram
Figure 2: HVD Nomad HA 6 nodes redundancy zones diagram
Load balancing
Use a layer 4 load balancer capable of handling TCP traffic to direct Nomad operator requests to HTTPS API port of the server nodes within your Nomad cluster. Any request sent to a standby node that requires an active node to process (e.g., job run/dispatch) will be proxied by the standby node to the active node.
Nomad server nodes also perform server-to-server communication to other nodes in the cluster over 4648/tcp.
This is used for functions critical to the integrity of the cluster itself, such as data replication or active node election.
Unlike operator requests, server-to-server traffic should not be load-balanced. Instead, each node must be able to communicate directly with all other nodes in the cluster.
TLS
To ensure the integrity and privacy of transmitted secrets, communications between Nomad operators and Nomad servers should be secured using TLS certificates that you trust.
Do not manage the TLS certificate for the Nomad cluster on the load balancer.
Instead, the certificate chain (i.e., a public certificate, private key, and certificate authority bundle from a trusted certificate authority) should be distributed onto the Nomad servers themselves, and the load balancer should be configured to pass through TLS connections to Nomad nodes directly.
Terminating TLS connections at the Nomad servers offers enhanced security by ensuring that a client request remains encrypted end-to-end, reducing the attack surface for potential eavesdropping or data tampering.
Key management
Nomad servers maintain an encryption keyring(opens in new tab) used to encrypt Variables and sign task workload identities.
You should configure Nomad servers to use an external KMS(opens in new tab) or Vault transit encryption(opens in new tab) to wrap the key material using the keyring configuration block(opens in new tab).
Backup snapshot storage
Automated snapshots should be saved to a storage medium, separate from the storage used for the Nomad data directories(opens in new tab). Snapshot storage does not require the same high IO-throughput requirements as the rest of Nomad, but it should be durable enough to ensure fast retrieval and restoration of backups when needed. To satisfy this requirement, you can use an object storage system, such as AWS S3, or a network-mounted filesystem, such as NFS.
Configuring the snapshots themselves, their frequency, and other operational considerations can be found in Nomad: Operating Guide.
Audit
Audit(opens in new tab) collects and keeps a detailed log of all Nomad requests and corresponding responses. Nomad operators can use these logs to ensure that Nomad is being used in a compliant manner, and to provide an audit trail for forensic analysis in the event of a security incident.To ensure the availability of audit log data, configure Nomad to use multiple audit destinations. Writing an additional copy of audit log data to a separate device can help prevent data loss in the event one device becomes unavailable, and can also help guard against data tampering.
Cluster architecture summary
To summarize, the HashiCorp Validated Design for a Nomad Enterprise cluster architecture is made up of the following components:
- 6 Nomad servers, deployed across three availability zones within a geographic region
- Using a redundancy zones topology, each node is configured as a voter or non-voter, with one of each per availability zone
- Locally-attached, high-IO storage for Nomad’s Storage
- A layer 4 (TCP) load balancer, with TLS certificates distributed to the Nomad nodes
- An object storage or network file system destination for storing automated snapshots
- Audit logs, configured to write to multiple destinations
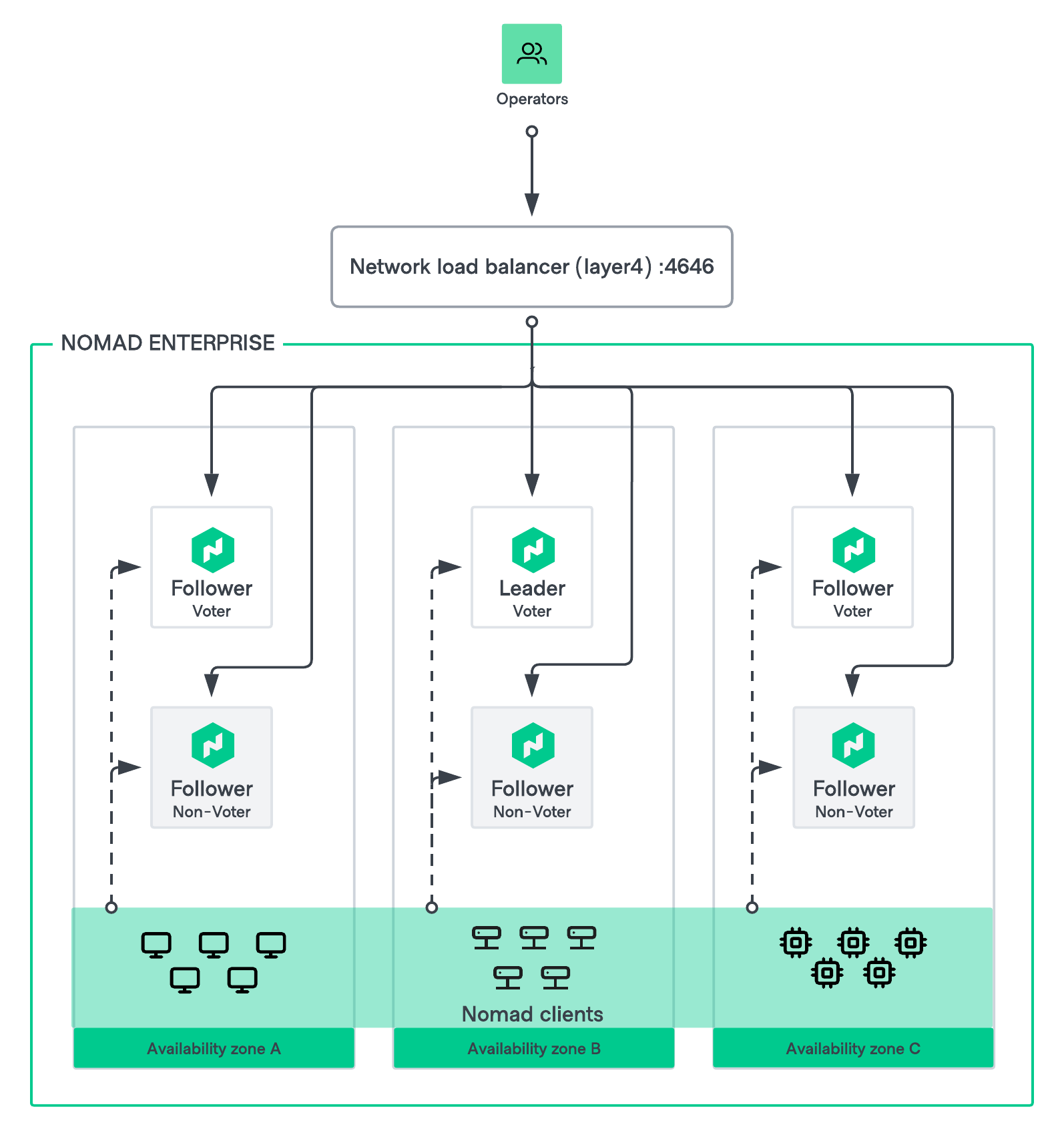 Figure 3: HVD Nomad cluster architecture diagram
Figure 3: HVD Nomad cluster architecture diagram