Discover Nomad reference architecture
This document provides recommended practices and a reference architecture for HashiCorp Nomad production deployments. This reference architecture conveys a general architecture that should be adapted to accommodate the specific needs of each implementation.
The following topics are addressed:
- Reference Architecture
- Deployment Topology within a Single Region
- Deployment Topology across Multiple Regions
- Network Connectivity Details
- Deployment System Requirements
- High Availability
- Failure Scenarios
This document describes deploying a Nomad cluster in combination with, or with access to, a Consul cluster. We recommend the use of Consul with Nomad to provide automatic clustering, service discovery, health checking and dynamic configuration.
Reference architecture
A Nomad cluster typically comprises three or five servers (but no more than seven) and a number of client agents. Nomad differs slightly from Consul in that it divides infrastructure into regions which are served by one Nomad server cluster, but can manage multiple datacenters or availability zones. For example, a US Region can include datacenters us-east-1 and us-west-2.
In a Nomad multi-region architecture, communication happens via WAN gossip. Additionally, Nomad can integrate easily with Consul to provide features such as automatic clustering, service discovery, and dynamic configurations. Thus we recommend you use Consul in your Nomad deployment to simplify the deployment.
In cloud environments, a single cluster may be deployed across multiple availability zones. For example, in AWS each Nomad server can be deployed to an associated EC2 instance, and those EC2 instances distributed across multiple AZs. Similarly, Nomad server clusters can be deployed to multiple cloud regions to allow for region level HA scenarios.
For more information on Nomad server cluster design, see the cluster requirements documentation.
The design shared in this document is the recommended architecture for production environments, as it provides flexibility and resilience. Nomad utilizes an existing Consul server cluster; however, the deployment design of the Consul server cluster is outside the scope of this document.
Nomad to Consul connectivity is over HTTP and should be secured with TLS as well as a Consul token to provide encryption of all traffic. This is done using Nomad's Automatic Clustering with Consul.
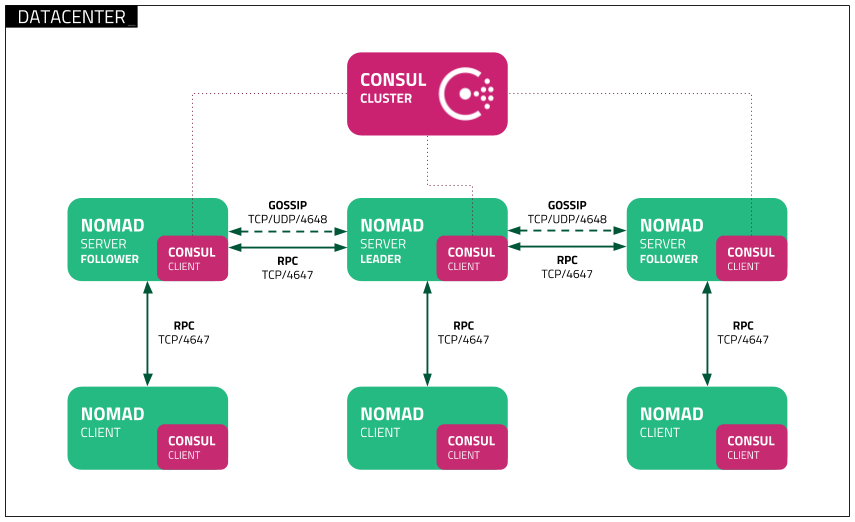
Deployment topology within a single region
A single Nomad cluster is recommended for applications deployed in the same region.
Each cluster is expected to have either three or five servers. This strikes a balance between availability in the case of failure and performance, as Raft consensus gets progressively slower as more servers are added.
The time taken by a new server to join an existing large cluster may increase as the size of the cluster increases.
Reference diagram
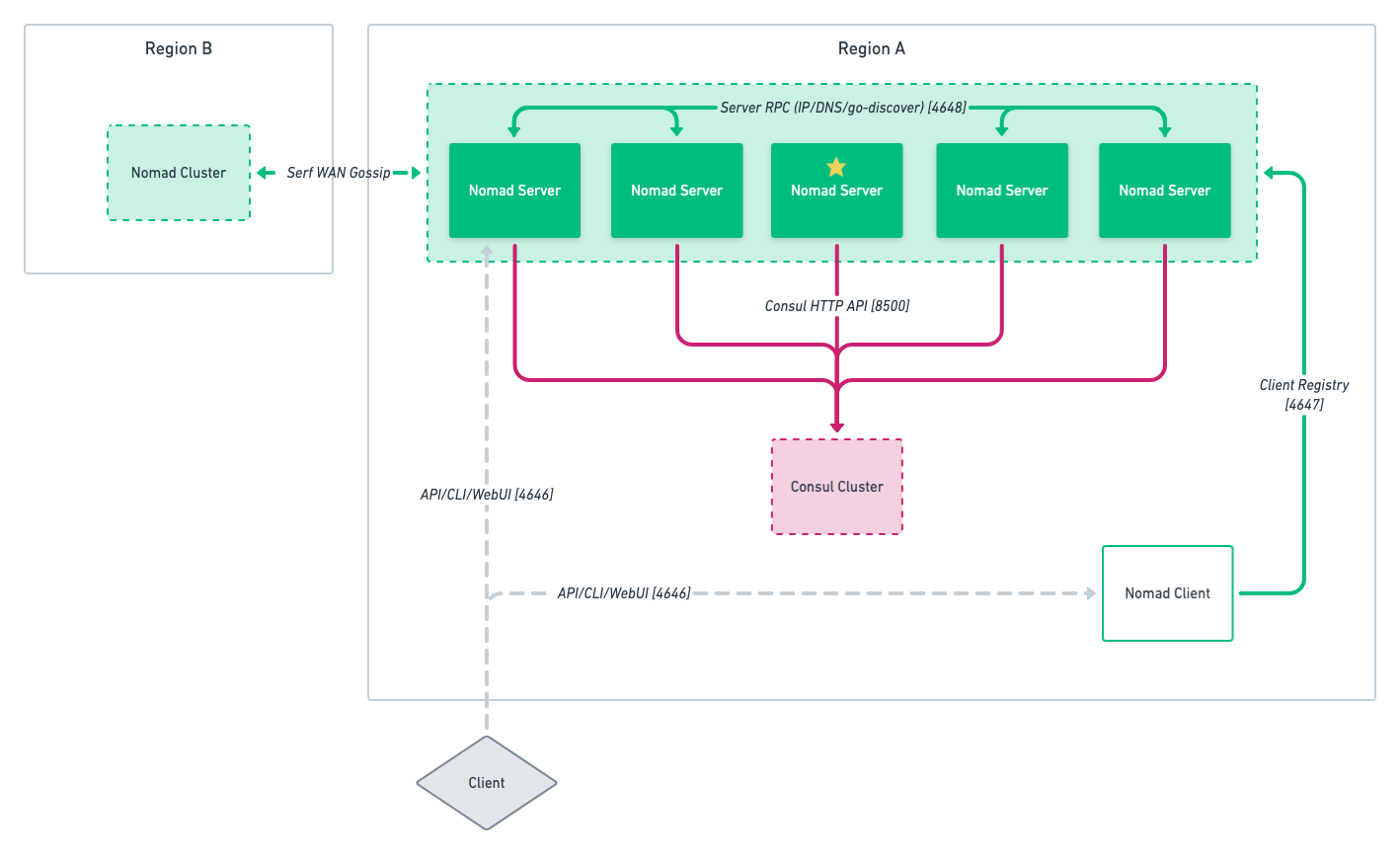
Deployment topology across multiple regions
By deploying Nomad server clusters in multiple regions, the user is able to interact with the Nomad servers by targeting any region from any Nomad server even if that server resides in a separate region. However, most data is not replicated between regions as they are fully independent clusters. The exceptions which are replicated between regions are:
Nomad server clusters in different datacenters can be federated using WAN links.
The server clusters can be joined to communicate over the WAN on port 4648.
This same port is used for single datacenter deployments over LAN as well.
Additional documentation is available to learn more about Nomad cluster federation.
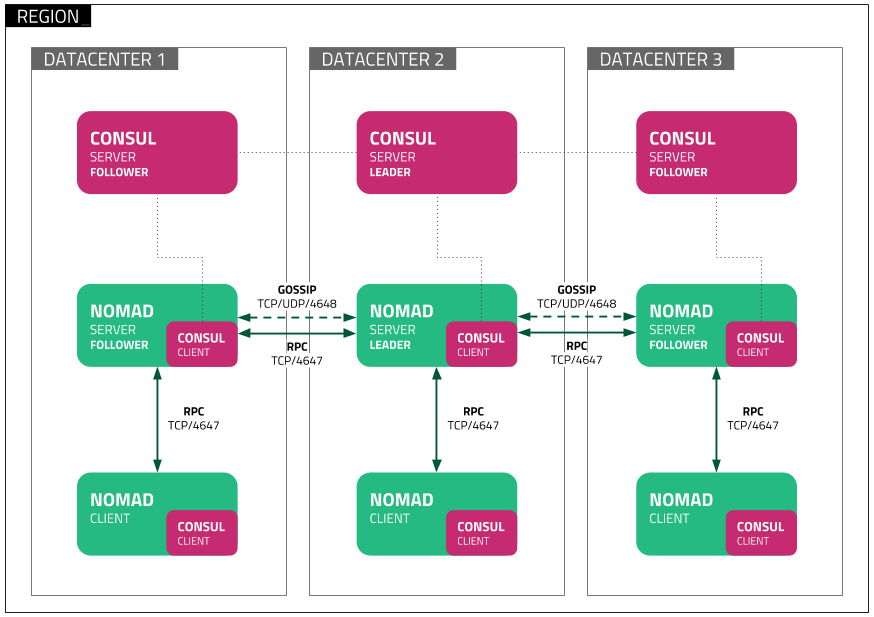
Network connectivity details
Nomad servers are expected to be able to communicate in high bandwidth, low latency network environments and have below 10 millisecond latencies between cluster members. Nomad servers can be spread across cloud regions or datacenters if they satisfy these latency requirements.
Nomad client clusters require the ability to receive traffic as noted in the Network Connectivity Details; however, clients can be separated into any type of infrastructure (multi-cloud, on-prem, virtual, bare metal, etc.) as long as they are reachable and can receive job requests from the Nomad servers.
Additional documentation is available to learn more about Nomad networking.
Deployment system requirements
Nomad server agents are responsible for maintaining the cluster state, responding to RPC queries (read operations), and for processing all write operations. Given that Nomad server agents do most of the heavy lifting, server sizing is critical for the overall performance efficiency and health of the Nomad cluster.
Nomad servers
| Type | CPU | Memory | Disk | Typical Cloud Instance Types |
|---|---|---|---|---|
| Small | 2-4 core | 8-16 GB RAM | 50 GB | AWS: m5.large, m5.xlarge |
| Azure: Standard_D2_v3, Standard_D4_v3 | ||||
| GCP: n2-standard-2, n2-standard-4 | ||||
| Large | 8-16 core | 32-64 GB RAM | 100 GB | AWS: m5.2xlarge, m5.4xlarge |
| Azure: Standard_D8_v3, Standard_D16_v3 | ||||
| GCP: n2-standard-8, n2-standard-16 |
Hardware sizing considerations
The small size would be appropriate for most initial production deployments, or for development/testing environments.
The large size is for production environments where there is a consistently high workload.
Nomad clients can be setup with specialized workloads as well. For example, if workloads require GPU processing, a Nomad datacenter can be created to serve those GPU specific jobs and joined to a Nomad server cluster. For more information on specialized workloads, see the documentation on job constraints to target specific client nodes.
High availability
A Nomad server cluster is the highly available unit of deployment within a single datacenter. A recommended approach is to deploy a three or five node Nomad server cluster. With this configuration, during a Nomad server outage, failover is handled immediately without human intervention.
When setting up high availability across regions, multiple Nomad server clusters are deployed and connected via WAN gossip. Nomad clusters in regions are fully independent from each other and do not share jobs, clients, or state. Data residing in a single region-specific cluster is not replicated to other clusters in other regions.
Failure scenarios
Typical distribution in a cloud environment is to spread Nomad server nodes into separate Availability Zones (AZs) within a high bandwidth, low latency network, such as an AWS Region. The diagram below shows Nomad servers deployed in multiple AZs promoting a single voting member per AZ and providing both AZ-level and node-level failure protection.
Additional documentation is available to learn more about cluster sizing and failure tolerances as well as outage recovery.
Availability zone failure
In the event of a single AZ failure, only a single Nomad server is affected which would not impact job scheduling as long as there is still a Raft quorum (that is, 2 available servers in a 3 server cluster, 3 available servers in a 5 server cluster, more generally:
quorum = floor( count(members) / 2) + 1
There are two scenarios that could occur should an AZ fail in a multiple AZ setup: leader loss or follower loss.
Leader server loss
If the AZ containing the Nomad leader server fails, the remaining quorum members would elect a new leader. The new leader then begins to accept new log entries and replicates these entries to the remaining followers.
Follower server loss
If the AZ containing a Nomad follower server fails, there is no immediate impact to the Nomad leader server or cluster operations. However, there still must be a Raft quorum in order to properly manage a future failure of the Nomad leader server.
Region failure
In the event of a region-level failure (which would contain an entire Nomad server cluster), clients are still able to submit jobs to another region that is properly federated. However, data loss is likely as Nomad server clusters do not replicate their data to other region clusters. See Multi-region Federation for more setup information.
Next steps
- Read Deployment Guide to learn the steps required to install and configure a single HashiCorp Nomad cluster.