Consul reference architecture
This guide describes recommended best practices for infrastructure architects and operators to follow when deploying Consul in a production environment. This guide includes general guidance as well as specific recommendations for popular cloud infrastructure platforms. These recommendations have also been encoded into official Terraform modules for AWS, Azure, and GCP.
Recommended Architecture
The following diagram shows the recommended architecture for deploying a single Consul cluster with maximum resiliency:
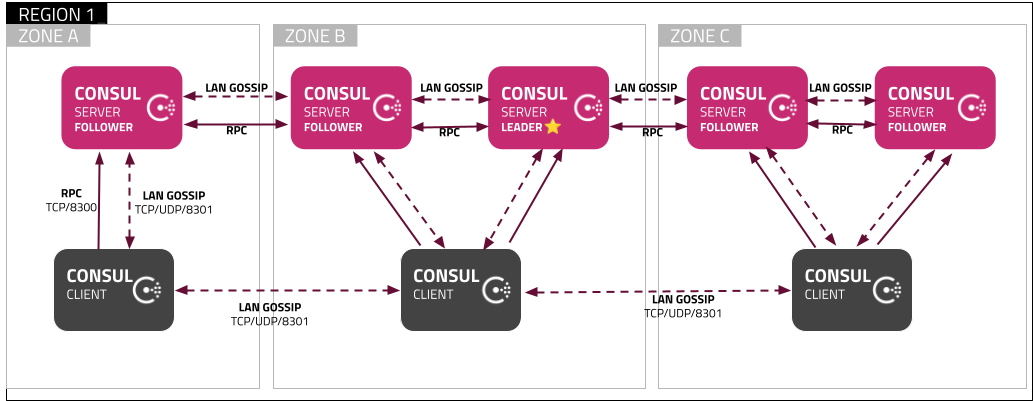
We recommend deploying 5 nodes within the Consul cluster distributed between three availability zones as this architecture can withstand the loss of two nodes from within the cluster or the loss of an entire availability zone. Together, these servers run the Raft-driven consistent state store for updating catalog, session, prepared query, ACL, and KV state.
If deploying to three availability zones is not possible, this same architecture may be used across one or two availability zones, at the expense of significant reliability risk in case of an availability zone outage. For more information on quorum size and failure tolerance for various cluster sizes, please refer to the Consul Deployment Table.
For Consul Enterprise customers, additional resiliency is possible by implementing a multi-cluster architecture, which allows for additional performance and disaster recovery options. See the Federate Multiple Datacenters Using WAN Gossip Learn tutorial for more information. Additionally, refer to the Scaling Considerations section below for Enterprise features that can affect the recommended architecture.
System Requirements
This section contains specific hardware capacity recommendations, network requirements, and additional infrastructure considerations. Since every hosting environment is different and every customer's Consul usage profile is different, these recommendations should only serve as a starting point from which each customer's operations staff may observe and adjust to meet the unique needs of each deployment.
Hardware sizing for Consul servers
We recommend that Consul servers in production run on hardware that meets the following requirements:
| CPU | Memory | Disk Capacity | Disk IO | Disk Throughput | Avg Round-Trip-Time | 99% Round-Trip-Time |
|---|---|---|---|---|---|---|
| 8-16 core | 32-64 GB RAM | 200+ GB | 7500+ IOPS | 250+ MB/s | Lower than 50ms | Lower than 100ms |
Hardware requirements increase based on the size of the Consul cluster, the number of client agents, and workload characteristics such as read-heavy and write-heavy usage. While Consul may run on smaller hardware configurations for testing and development purposes, we recommend these minimum specifications to ensure optimal performance and reliability in production environments and avoid having to upgrade hardware during a capacity outage.
The following table provides our recommended starting point for hardware instances on each major cloud infrastructure provider.
| Provider | Instance/VM Types | Disk Volume Specs |
|---|---|---|
| AWS | m5.2xlarge, m5.4xlarge | 200+GB gp3, 10000 IOPS, 250MB/s |
| Azure | Standard_D8s_v3, Standard_D16s_v3 | 2048GB* Premium SSD, 7500 IOPS, 200MB/s |
| GCP | n2-standard-8, n2-standard-16 | 1000GB* pd-ssd, 30000 IOPS, 480MB/s |
For further guidance on hardware sizing for Consul servers based on workload characteristics, please refer to the Capacity Planning documentation.
Hardware sizing considerations
Since Consul server agents run a consensus protocol to process all write and read operations, server performance is critical for overall throughput and health of a Consul cluster. Server agents are generally I/O bound for writes and CPU bound for reads. Additionally, larger environments may require additional tuning (e.g. raft multiplier) for optimal performance. For more information on server requirements, review the server performance documentation.
Network latency and bandwidth
Consul uses the gossip protocol to share information across agents. To function properly, you cannot exceed the protocol’s maximum latency threshold between available zones. The latency threshold is calculated according to the total round trip time (RTT) for communication between all agents. Other network usages outside of Gossip are not bound by these latency requirements (i.e. client to server RPCs, HTTP API requests, xDS proxy configuration, DNS).
For data sent between all Consul agents the following latency requirements must be met:
- Average RTT for all traffic cannot exceed 50ms.
- RTT for 99 percent of traffic cannot exceed 100ms.
The amount of network bandwidth used by Consul will depend entirely on the specific usage patterns. In many cases, even a high request volume will not translate to a large amount of network bandwidth consumption. However, all data written to Consul will be replicated across all server agents. It's also important to consider bandwidth requirements to other external systems such as monitoring and logging collectors.
Other network activity outside of gossip, such as client-to-server RPC, HTTP API requests, xDS proxy configuration, and DNS, are not bound by these latency requirements. However, high network latency can still impact overall performance of those operations.
For additional details about DNS Forwarding, DNS Caching, and other production networking details, please refer to the Production Readiness Checklist.
Network connectivity
LAN gossip occurs between all agents in a single datacenter with each agent sending a periodic probe to random agents from its member list. Both client and server agents participate in the gossip.
In a larger network that spans L3 segments, traffic typically traverses through a firewall and/or a router. You must update your ACL or firewall rules to allow the following ports:
| Name | Port / Protocol | Source | Destination | Description |
|---|---|---|---|---|
| RPC | 8300 / TCP | All agents (client & server) | Server agents | Used by servers to handle incoming requests from other agents. |
| Serf LAN | 8301 / TCP & UDP | All agents (client & server) | All agents (client & server) | Used to handle gossip in the LAN. Required by all agents. |
| Serf WAN | 8302 / TCP & UDP | Server agents | Server agents | Used by server agents to gossip over the WAN to other server agents. Only used in multi-cluster environments. |
| HTTP/HTTPS | 8500 & 8501 TCP | Localhost of client or server agent | Localhost of client or server agent | Used by clients to talk to the HTTP API. HTTPS is disabled by default. |
| DNS | 8600 TCP & UDP | Localhost of client or server agent | Localhost of client or server agent | Used to resolve DNS queries. |
| gRPC (Optional) | 8502 TCP | Envoy proxy | Client agent or server agent that manages the sidecar proxies service registration | Used to expose the xDS API to Envoy proxies. Disabled by default. |
| Sidecar Proxy (Optional) | 21000 - 21255 TCP | All agents (client & server) | Client agent or server agent that manages the sidecar proxies service registration | Port range used for automatically assigned sidecar service registrations. |
If you deploy on Kubernetes with the AWS VPC CNI or other CNI implementations,
ensure that both inbound and outbound traffic on these ports is permitted. Blocking ports such as
8300, 8301, or 8302 for either inbound or outbound traffic can disrupt Consul’s gossip and RPC communication and result in cluster instability.
For more information about the ports that Consul uses, check the Required Ports page or the ports section of the agent configuration documentation.
Guidance for Network Policy Configuration
When deploying Consul on Kubernetes with the AWS VPC CNI (or any other CNI), ensure you explicitly allow:
- Inbound and outbound for ports
8300,8301,8302among Consul servers and clients in the same datacenter. - Proper port ranges for sidecar proxies if Consul service mesh is enabled.
- Minimal latency between nodes to meet the gossip protocol’s requirements.
Checklist:
- Security Groups and Firewalls: Confirm rules for
8300(TCP),8301(TCP & UDP),8302(TCP & UDP). - Kubernetes NetworkPolicy: If using NetworkPolicy objects, verify all needed ports are explicitly allowed.
- Load Balancers or NAT Gateways: Check if your traffic paths require additional rules or NAT exceptions.
- High Availability: Validate multi-AZ deployments for latency with the constraints: Average RTT < 50 ms, 99% RTT < 100 ms.
Networking Best Practices
- Maintain Low Latency: Keep RTT below 50 ms average for all nodes in a datacenter to ensure stable gossip.
- Open Required Ports:
8300(RPC),8301(LAN gossip),8302(WAN gossip), plus8500(HTTP),8501(HTTPS) and8600(DNS). Both inbound and outbound rules must allow these ports. - Check Connectivity Regularly: Use scripts or Consul CLI command
consul troubleshoot portsto verify that there are no blocked ports. - Monitor Logs and Alerts: Set up alerts for connection failures, timeouts, or
DENYmessages in flow logs. - Iterate on Logging: When you find connectivity failures, log details such as IP, port, and error type to speed up diagnosis.
Security considerations
Network communication to Consul agents should be secured by configuring encryption, authentication, and authorization in Consul. Access Control Lists (ACLs) authenticate requests and authorize access to resources in Consul. Symmetric encryption is used for the gossip protocol, and TLS is used to encrypt and authenticate connections for the HTTP, RPC, and gRPC protocols.
In Consul service mesh, mutual TLS is implemented by sidecar proxies to encrypt and authenticate service-to-service communication. Consul intentions provide authorization for incoming connections based on service identities encoded in TLS certificates.
Consul supports two certificate authorities (CA). The Agent CA issues TLS certificates for Consul agent RPC communication. The service mesh CA issues TLS certificates for each service in Consul service mesh for mutual TLS and for Consul client agents when auto-encrypt is enabled.
For detailed security recommendations, follow the Consul Security Considerations part of this guide.
Scaling considerations
The recommended maximum size for a single datacenter is 5,000 Consul client agents. This recommendation is not solely based on scalability but also considers impact and recovery time if an entire datacenter fails. For a write-heavy and/or a read-heavy datacenter, you may need to reduce the maximum number of agents further depending on the number and the size of KV pairs and the number of watches. As you add more client agents, it takes more time for gossip to converge. Similarly, when a new server agent joins an existing multi-thousand node datacenter with a large KV store, it may take more time to replicate the store to the new server's log and the update rate may increase.
For these reasons, it is important that a baseline is established for these metrics and that a monitoring tool is configured for setting thresholds and alerts. For additional information on the available metrics to monitor, please refer to the Consul Telemetry documentation. Additionally, please refer to the Production Readiness Checklist for suggestions on specific metrics relating to appropriately sized instances.
While many of our users have successfully scaled Consul to tens of thousands of nodes per cluster, scaling is highly dependent on Consul’s workload for a specific deployment and use case. As with many scaling problems, there is no “one size fits all” solution. At scale, customers need to optimize for stability at the gossip layer. Significant factors include:
How fast nodes are joining/leaving/failing: large one-time spikes or persistent gossip churn will stress the system far more than a larger number of Consul catalog services or higher Consul KV read rate.
Total size of the gossip pool: the more nodes are in a datacenter/segment, the more stress is put on the gossip layer.
Consul datacenter scaling
Once a datacenter has reached the maximum recommended size of 5,000 Consul client agents, there are a couple of different recommended approaches which can assist with growing the datacenter to accommodate additional capacity.
Adding an additional Consul datacenter is a good approach if nodes are spread across separate physical locations (e.g. across different regions)
Adding network segments is a good approach if every segment has low latency between clients and servers (e.g. within the same availability zone/region).
Enterprise feature: enhanced read scalability
Read-heavy clusters (e.g. high RPC call rate, heavy DNS usage, etc.) will generally be bound by CPU and may take advantage of the read replicas Enterprise feature for improved scalability. This feature allows additional Consul servers to be introduced as non-voters. As a non-voter, the server will still participate in data replication, but it will not block the leader from committing log entries. Additional information can be found in the Server Performance section of the Consul product documentation.
Write-heavy clusters
Write-heavy clusters (e.g. high rate of agent joins/leaves, high K/V usage,etc.) will generally be bound by disk I/O because the underlying Raft log store performs a sync to disk every time an entry is appended. The disk recommendations in the hardware sizing section above should be sufficient for most workloads. Additional information can be found in the Server Performance section of the Consul product documentation.
Failure tolerance characteristics
When deploying a Consul cluster, it’s important to consider and design for the specific requirements for various failure scenarios:
Node failure
Consul allows for individual node failure by replicating all data between each server agent of the cluster. If the leader node fails, the remaining cluster members will elect a new leader following the Raft protocol. To allow for the failure of up to two nodes in the cluster, the ideal size is five nodes for a single Consul cluster.
Availability zone failure
By deploying a Consul cluster in the recommended architecture across three availability zones, the Raft consensus algorithm is able to maintain consistency and availability given the failure of any one availability zone.
In cases where deployment across three availability zones is not possible, the failure of an availability zone may cause the Consul cluster to become inaccessible or unable to elect a leader. In a two availability zone deployment, for example, the failure of one availability zone would have a 50% chance of causing a cluster to lose its Raft quorum and be unable to service requests.
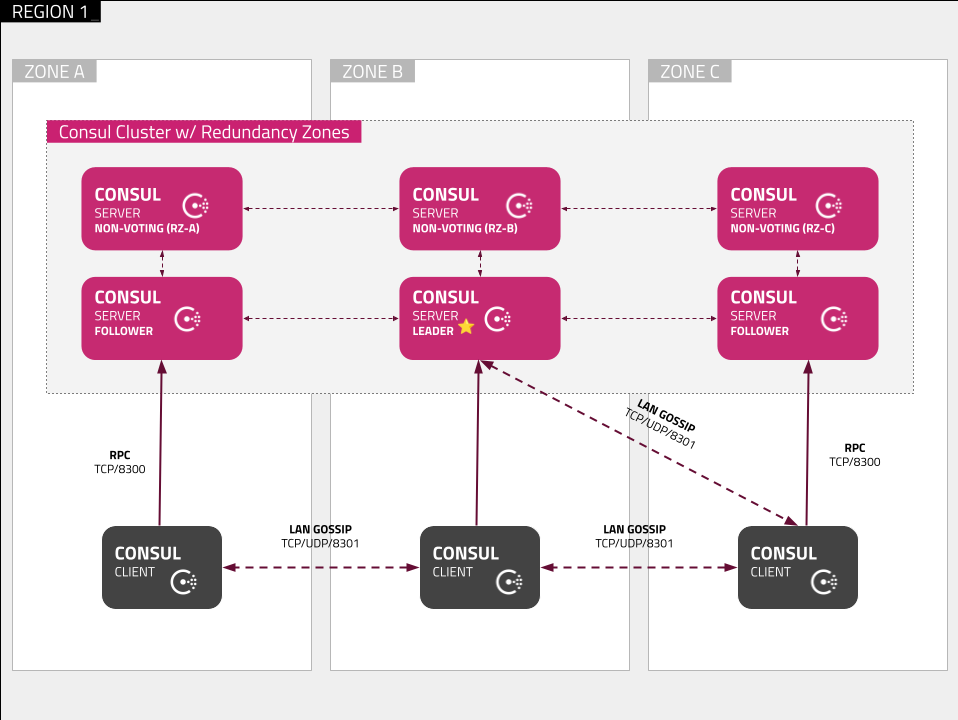
Enterprise feature: redundancy zones
To further improve resiliency and scaling of the Consul cluster, Redundancy Zones can be configured. Using Autopilot, you can add “non-voting” servers to your datacenter that will be promoted to the "voting" status in case of voting server failure.
Region failure
In the event of a total region failure, Consul and your services are likely down. To architect against this situation, deploy Consul and your services in multiple regions with a global failover policy that reroutes network traffic to the alternate region during a disaster. Deploying identical Consul servers and services across multiple cloud regions satisfies datacenter latency requirements and limits the blast radius during large-scale disasters.
Cluster failure
Consul’s failure model is based on graceful degradation. If the system gets into a state where it cannot service read requests , components fail static and continue using the last-known good configuration. In the event of a cluster outage, failing statically provides services with the ability to continue working as long as no changes are made to the system. Refer to the Disaster recovery for Consul clusters tutorial for an example that restores a Consul cluster in this situation.
Service failure
To architect against outages caused by disasters that impact services registered with Consul, use cluster peering failover with sameness groups. With this setup, Consul can transparently failover requests to an unhealthy service to the same service in a different region and datacenter.
Glossary
Consul datacenter
In most cases, a Consul datacenter is defined as a single physical datacenter or a single cloud region. While there are exceptions to this rule, the underlying philosophy is that a Consul datacenter is a LAN construct and is optimized for LAN latency. The communication protocols that the server processes use to coordinate their actions, and that both server and client processes communicate with each other, are optimized for LAN bandwidth.
Gossip
The gossip protocol is used by Consul to manage group membership of the cluster and to send broadcast messages. The version of Gossip used for Consul has been improved upon from other versions which are commonly used within distributed systems. For more information, please refer to the Consul architecture section within product documentation.
Consensus
Consensus is one of the required components for reliable, distributed computing in a world of unreliable hardware and software. A distributed system must be able to reach some kind of consensus; an agreement about which nodes are in charge, the current state, committed transactions, etc. -- even if all nodes do not share the same state or view of the environment. Distributed systems usually use an algorithm (i.e. a defined process) for reaching consensus.
Consul leverages the Raft consensus algorithm. The Raft protocol allows for nodes to be in one of 3 states: leader, follower, or candidate. Only Consul server agents leverage the consensus protocol, as client agents only forward requests to server agents. Raft leverages RPC for communication between server agents and client agents. For additional information, please refer to the Consensus Protocol section of the Consul product documentation.
Raft
Raft is the consensus algorithm that Consul uses to respond to client requests and replicate information (logs) between server agents. Information flows unidirectionally from the leader to the other server agents. For additional information, please refer to the Consensus Protocol section of the Consul product documentation.
Failure domain
A failure domain identifies the scope within which the service provider expects certain failures to be contained and for certain availability and performance characteristics to hold true. Since Consul is a highly-available, clustered service the most reliable Consul deployments are spread across multiple failure domains. In the context of a Consul cluster, a failure domain can represent an availability zone, an availability set, a region, and a physical rack or datacenter. The table below depicts the various types of failure domains for the major cloud providers and on premises resource locations.
| Resource Location | Failure Domains | Scope of Failure | Latency |
|---|---|---|---|
| AWS | Availability zones (AZ), Regions | Datacenter, Region | 1-2 ms between AZs, 10's-100's ms between regions |
| Azure | Availability sets (AS), Availability zones, Regions | Physical Server Rack, Datacenter, Region | <1 ms between availability sets, <2ms between AZs, 10's-100's ms between regions |
| GCP | Availability zones, Regions | Datacenter, Region | <1ms between AZs, 10's-100's ms between datacenters |
| On-premises | Separate racks, Highly available networking/cooling Anti-affinity rules | Physical rack, Physical switch, Cooling device, VM/Container high availability | <1 ms latency *This may vary depending on environment specifics |
Availability zone
In a cloud environment, “Availability Zones” represent geographically separate infrastructure with fast, low-latency networks between them. Within an on-premises infrastructure this would equate to separate physical server racks (within a single datacenter) with their own independent network, power, and cooling.
Region
A region is a collection of one or more availability zones on a low-latency network. Regions are typically separated by significant distances. A region could host one or more Consul clusters, but a single Consul cluster would not be spread across multiple regions due to network latency issues. See the Consul Multi-Cluster Reference Architecture for more information.
Next steps
- Consul Deployment Guide
- Production Readiness Checklist
- Consul Disaster Recovery Considerations
- Consul Security Considerations