Disaster recovery for Consul clusters
Every platform should be able to recover from disasters. This tutorial provides you with the guidance you need to recover from disaster when running Consul, from the loss of a single server node to a larger outage that disrupts a cluster's Raft operations. The recovery procedure is intended for virtual machines, but it also applies to containers and bare metal servers. In this scenario, there are three AWS EC2 instances running Consul server agents. In this tutorial you will:
- deploy three Consul servers in EC2 instances on AWS.
- simulate an outage of a single Consul server instance and its recovery.
- simulate an outage of two Consul server instances.
- perform a
peers.jsonrecovery on the remaining Consul server instance. - join two new Consul server instances replacing the lost ones.
Prerequisites
The tutorial assumes that you are familiar with Consul and its core functionality. If you are new to Consul, refer to the Consul Getting Started tutorials collection.
For this tutorial, you need:
- An AWS account configured for use with Terraform
- terraform >= 1.0
- consul >= 1.18.1
- git >= 2.0
- jq v1.6 or later
Clone GitHub repository
Clone the GitHub repository containing the configuration files and resources.
$ git clone https://github.com/hashicorp-education/learn-consul-disaster-recovery
Change the working directory to the repository folder.
$ cd learn-consul-disaster-recovery/
Review repository contents
This repository contains Terraform configurations and files to to spin up the initial infrastructure and deploy a Consul cluster that includes 3 server nodes.
The repo contains the following directories and files:
instance-scripts/directory contains the provisioning scripts and configuration files used to bootstrap the EC2 instancesprovisioning/directory contains configuration file templatesconsul-instances.tfdefines the EC2 instances for the Consul serversoutputs.tfdefines outputs you will use to authenticate and connect to your EC2 instancesproviders.tfdefines AWS provider definitions for Terraformvariables.tfdefines variables you can use to customize the tutorialvpc.tfdefines the AWS VPC resources
The configuration in the repository provisions the following billable resources:
- An AWS VPC
- An AWS key pair
- A set of three AWS EC2 instances
Deploy infrastructure and demo application
Initialize your Terraform configuration to download the necessary providers and modules.
$ terraform init
Initializing the backend...
Initializing provider plugins...
## ...
Terraform has been successfully initialized!
## …
Then, deploy the resources. Enter yes to confirm the run.
$ terraform apply
## ...
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
## ...
Apply complete! Resources: 22 added, 0 changed, 0 destroyed.
Configure the SSH Key manager as described in the next section, and read through the following description of the Terraform configuration while you wait for your infrastructure to deploy.
Connect to your infrastructure
Configure your SSH key manager agent to use the correct SSH key identity file, so that you will be able to log into the instances.
$ ssh-add tls-key.pem
Identity added: tls-key.pem (tls-key.pem)
Next, create environment variables for the IP address of each Consul server. These variables simplify operations later.
$ export CONSUL_SERVER0=ubuntu@$(terraform output -json consul_server_ips | jq -r '.[0]') && \
export CONSUL_SERVER1=ubuntu@$(terraform output -json consul_server_ips | jq -r '.[1]') && \
export CONSUL_SERVER2=ubuntu@$(terraform output -json consul_server_ips | jq -r '.[2]') && \
env | grep CONSUL_SERVER
The command prints out the contents of the environment variables to make sure they are populated correctly.
CONSUL_SERVER0=ubuntu@3.125.49.255
CONSUL_SERVER1=ubuntu@52.29.6.214
CONSUL_SERVER2=ubuntu@18.153.74.109
Review Terraform configuration for server instances
Open consul-instances.tf. This Terraform configuration creates:
- a TLS key pair that you can use to login to the server instances
- a couple of AWS IAM policies for the instances so they can use Consul cloud join
- one group of EC2 instances as Consul servers
The EC2 instance uses a provisioning script instance-scripts/setup.sh that is executed by the cloud-init subsystem to automate the Consul client configuration and provisioning. This script installs the Consul agent package on the instance and then automatically generates a Consul agent configuration for each Consul server instance.
Inspect the consul-server-group resource in the consul-instances.tf file. We have trimmed the output here for brevity.
consul-instances.tf
resource "aws_instance" "consul-server-group" {
count = 3
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
iam_instance_profile = aws_iam_instance_profile.profile_manage_instances.name
##...
setup = base64gzip(templatefile("${path.module}/instance-scripts/setup.sh", {
hostname = "consul-server${count.index}",
consul_ca = base64encode(tls_self_signed_cert.consul_ca_cert.cert_pem),
consul_config = base64encode(templatefile("${path.module}/provisioning/templates/consul-server.json", {
datacenter = var.datacenter,
token = random_uuid.consul_bootstrap_token.result,
retry_join = "provider=aws tag_key=learn-consul-dr tag_value=join",
})),
consul_acl_token = random_uuid.consul_bootstrap_token.result,
consul_version = var.consul_version,
vpc_cidr = module.vpc.vpc_cidr_block,
})),
})
tags = {
Name = "consul-server${count.index}"
learn-consul-dr = "join"
}
}
The count directive instructs Terraform to deploy three instances of this resource. Then, each hostname is dynamically generated on line 10 by appending the instance number to the end of the consul-server string.
The Consul configuration file is generated on line 12 by passing a few variables to the template in provisioning/templates/consul-server.json. The variables are the datacenter, the instance token, and the configuration for the Consul cloud autojoin feature. After rendering the template, the script saves the configuration on the Consul server node. You will explore this configuration in the next section of this tutorial.
Finally, the cloud instance is tagged on line 25 with the learn-consul-dr key and its value join. This key and value identify the cloud auto-join parameters so that after a Consul server starts, it connects to the other servers in the cluster.
Review Consul server configuration
Inspect the Consul configuration file on the first Consul instance. If you get an error that there is no such file or directory, this error means that the provisioning is still working on the instance and you must wait for a few minutes before you proceed.
$ ssh $CONSUL_SERVER0 "cat /etc/consul.d/client.json"
{
"acl": {
"enabled": true,
"down_policy": "async-cache",
"default_policy": "deny",
"tokens": {
"agent": "<redacted>",
"default": "<redacted>",
"initial_management": "<redacted>"
}
},
"datacenter": "dc1",
"retry_join": [
"provider=aws tag_key=learn-consul-dr tag_value=join"
],
"encrypt": "",
"encrypt_verify_incoming": false,
"encrypt_verify_outgoing": false,
"server": true,
"bootstrap_expect": 3,
"log_level": "INFO",
"ui_config": {
"enabled": true
},
"tls": {
"defaults": {
"ca_file": "/etc/consul.d/ca.pem",
"verify_outgoing": false
}
},
"ports": {
"grpc": 8502
},
"bind_addr": "{{ GetPrivateInterfaces | include \"network\" \"10.0.0.0/16\" | attr \"address\" }}"
}
Terraform deployed the other Consul server nodes with a configuration identical to this one. They are a part of the dc1 datacenter. These nodes discover other Consul nodes to join into a cluster by using the cloud auto-join feature. In this case, the cloud auto-join reports the addresses of VM instances that have the learn-consul-dr tag with the join value.
There are several types of cluster outages, depending on the total number of server nodes and number of failed server nodes. In order to understand this tutorial, you must be familiar with the concept of Consul quorum and how many server nodes are needed to keep quorum. This tutorial will outline how to recover from:
- Server failure in a multi-server cluster that keeps quorum.
- Server failure in a multi-server cluster that loses quorum. This situation occurs when one or more servers fail and the number of remaining alive Consul servers are not enough to form quorum. This scenario can result in data loss.
Server failure in a multi-server cluster keeping quorum
In this section, you will simulate a failure of the consul-server0 Consul server node. The cluster can survive the failure of one node in its current state. When one node fails, enough the Consul servers are in the alive state to retain quorum.




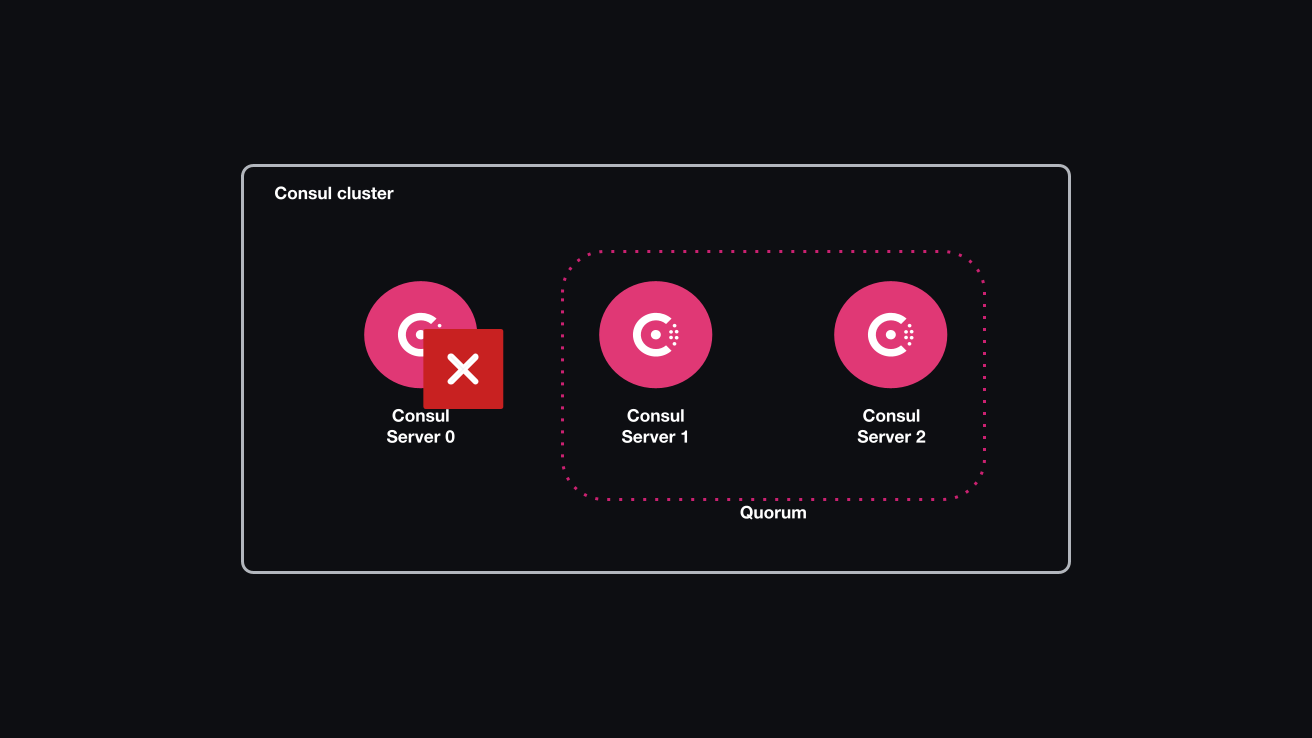
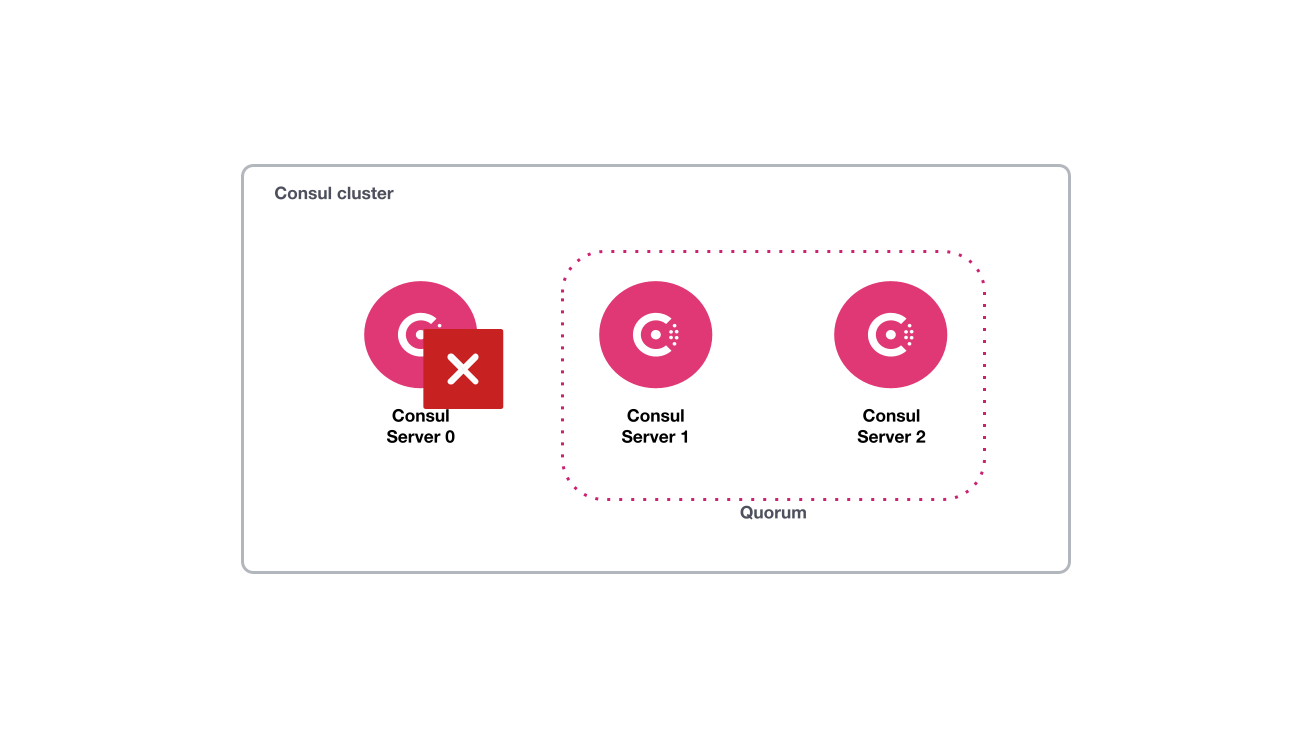
Inspect the current failure tolerance by running the following command against any of the participating servers.
$ ssh $CONSUL_SERVER1 "consul operator autopilot state | grep Failure"
Failure Tolerance: 1
Optimistic Failure Tolerance: 1
Now, kill the Consul server agent running on that node to simulate a node failure.
$ ssh $CONSUL_SERVER0 "sudo systemctl kill --signal=SIGKILL consul"
Check that the Consul service is not running.
$ ssh $CONSUL_SERVER0 "systemctl status consul"
● consul.service - "HashiCorp Consul - A service mesh solution"
Loaded: loaded (/usr/lib/systemd/system/consul.service; enabled; vendor preset: enabled)
Active: failed (Result: signal) since Mon 2024-03-18 15:48:12 UTC; 3min 30s ago
Docs: https://www.consul.io/
Process: 7065 ExecStart=/usr/bin/consul agent -config-dir=/etc/consul.d/ (code=killed, signal=KILL)
Main PID: 7065 (code=killed, signal=KILL)
[INFO] agent.server.serf.wan: serf: EventMemberJoin: consul-server2.dc1 10.0.4.148
[INFO] agent.server: Handled event for server in area: event=member-join server=consul-server2.dc1 area=wan
[INFO] agent.server.serf.wan: serf: EventMemberJoin: consul-server1.dc1 10.0.4.72
[INFO] agent.server: Handled event for server in area: event=member-join server=consul-server1.dc1 area=wan
[INFO] agent.server: Adding LAN server: server="consul-server1 (Addr: tcp/10.0.4.72:8300) (DC: dc1)"
[INFO] agent.server: New leader elected: payload=consul-server1
[INFO] agent: Synced node info
consul-server0 systemd[1]: consul.service: Main process exited, code=killed, status=9/KILL
consul-server0 systemd[1]: consul.service: Failed with result 'signal'.
Inspect the status of the Consul cluster from node consul-server1. Notice that the consul-server0 node status is left.
$ ssh $CONSUL_SERVER1 "consul members"
Node Address Status Type Build Protocol DC Partition Segment
consul-server0 10.0.4.235:8301 left server 1.18.1 2 dc1 default <all>
consul-server1 10.0.4.72:8301 alive server 1.18.1 2 dc1 default <all>
consul-server2 10.0.4.148:8301 alive server 1.18.1 2 dc1 default <all>
Because only one node from three has failed, the cluster has maintained quorum of 2 nodes. Verify that the cluster has a leader and is operational by running the following Consul operator command.
$ ssh $CONSUL_SERVER1 "consul operator raft list-peers"
Node ID Address State Voter RaftProtocol Commit Index Trails Leader By
consul-server1 a6fbf1fc-5198-1120-5363-7e4b6eb8639b 10.0.4.72:8300 leader true 3 66 -
consul-server2 5d0fd5a0-af8e-963d-31a5-59aae879b6af 10.0.4.148:8300 follower true 3 66 0 commits
To work and maintain quorum a Consul cluster needs at least half of the initial server nodes plus one to stay up and running. In this case, with an initial number of three nodes, the cluster needs at least two server nodes to function. If the cluster lost one more server it would not meet the quorum requirements and would fail. Inspect the current fault-tolerance level of the Consul cluster on consul-server1 again and notice that the number of nodes that can fail before the cluster becomes inoperable is zero.
$ ssh $CONSUL_SERVER1 "consul operator autopilot state | grep Failure"
Failure Tolerance: 0
Optimistic Failure Tolerance: 0
In a failure case similar to this one, and if the failed server is recoverable, the best option is to bring it back online and have it rejoin the cluster with the same IP address and node name. In this case, we can either restart the Consul process using the systemd manager or restart the VM instance.
If a process or VM restart is impossible, rebuild the Consul server node and replace it with a node that has the same IP address and name as the failed node. After the replacement node is online and has rejoined, node-specific data like tokens and policies will be repopulated by the cluster's leader. No further recovery is needed.
If building a new server node with the same IP and node name is not an option, you must add another server node to the Consul cluster. In this case, you must recreate node-specific data like tokens and policies for the new node.
Now, restore the Consul cluster state by restarting the Consul agent on node consul-server0 and verify it has rejoined the cluster.
$ ssh $CONSUL_SERVER0 "sudo systemctl start consul" && \
sleep 5 && \
ssh $CONSUL_SERVER0 "consul members"
Node Address Status Type Build Protocol DC Partition Segment
consul-server0 10.0.4.235:8301 alive server 1.18.1 2 dc1 default <all>
consul-server1 10.0.4.72:8301 alive server 1.18.1 2 dc1 default <all>
consul-server2 10.0.4.148:8301 alive server 1.18.1 2 dc1 default <all>
After restoring the failed server node, inspect the current fault tolerance level on the Consul cluster. Verify that the number of nodes that can fail before the cluster becomes inoperable returned to 1.
$ ssh $CONSUL_SERVER1 "consul operator autopilot state | grep Failure"
Failure Tolerance: 1
Optimistic Failure Tolerance: 1
Server failure in a multi-server cluster losing quorum
When losing multiple Consul servers results in a loss of quorum and a complete outage, partial recovery is possible using data on the remaining servers in the cluster. There may be data loss in this situation because multiple servers were lost, so information committed to the Raft index could be incomplete. The recovery process implicitly commits all outstanding Raft log entries, so it is also possible to commit data that was uncommitted before the failure.
In order to simulate a Consul cluster losing quorum, you will perform the following steps:
- Kill the Consul server agent on nodes
consul-server0andconsul-server1to simulate instance loss and loss of quorum - Kill the Consul server agent on node
consul-server2to simulate an instance crash - Restart the Consul server agent on node
consul-server2to observe the cluster cannot recover with one node - Perform a manual recovery of the cluster only with node
consul-server2 - Redeploy nodes
consul-server0andconsul-server1to bring the cluster to a healthy three-node state


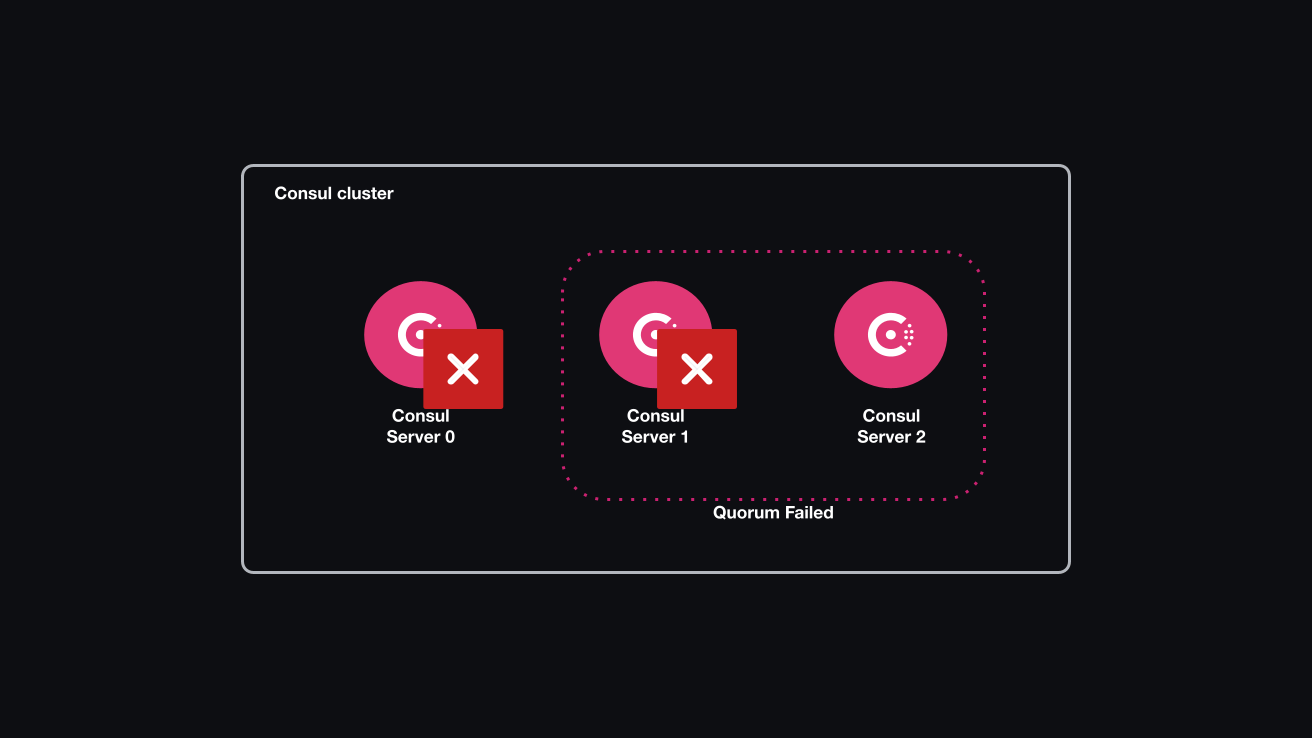
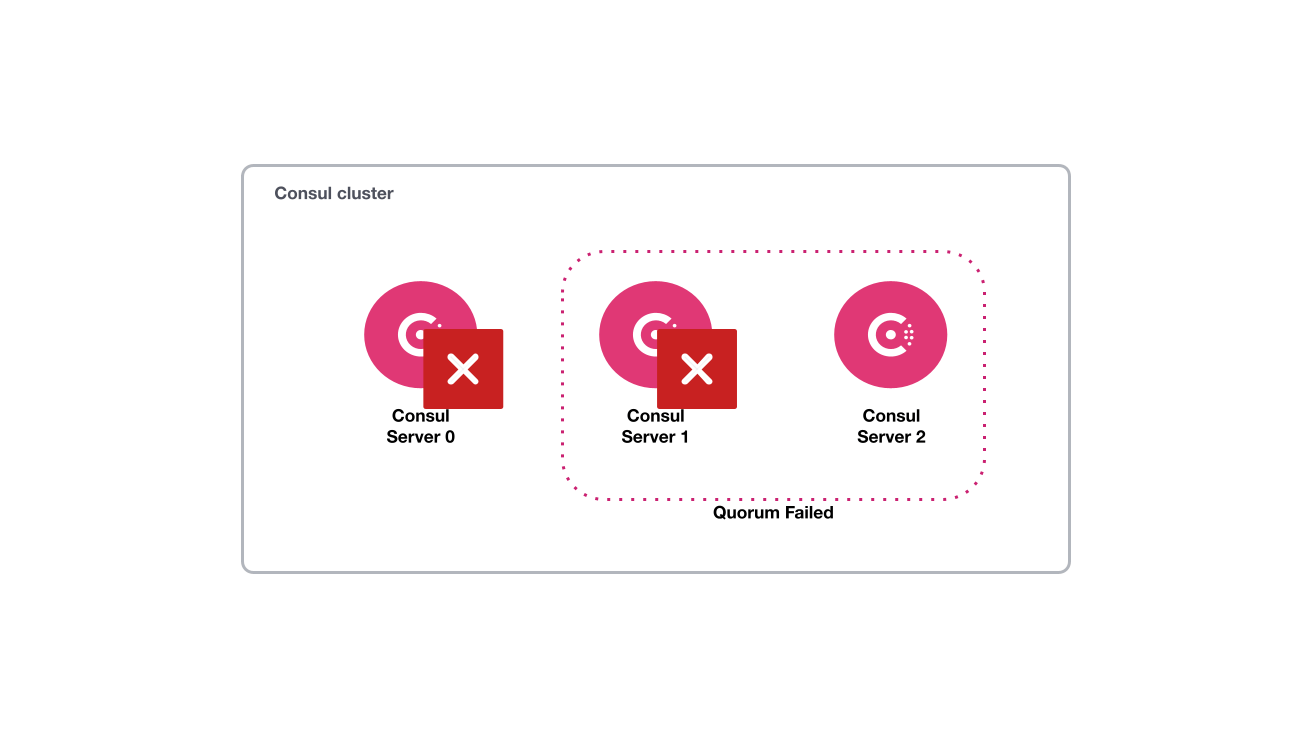


First, simulate an outage by killing two Consul server agents at the same time. One node will remain operational, which is below the minimum quorum for a three-node cluster.
$ ssh $CONSUL_SERVER0 "sudo systemctl kill --signal=SIGKILL consul" && \
ssh $CONSUL_SERVER1 "sudo systemctl kill --signal=SIGKILL consul"
Verify that the cluster has no leader even though the node consul-server2 is still alive.
$ ssh $CONSUL_SERVER2 'consul operator raft list-peers'
Error getting peers: Failed to retrieve raft configuration: Unexpected response code: 500 (No cluster leader)
Stop the last Consul agent node to finish simulating a complete outage scenario.
$ ssh $CONSUL_SERVER2 "sudo systemctl kill --signal=SIGKILL consul"
At this point, the easiest and fastest approach to recovery is to rebuild an independent fresh cluster and restore a backup from the old cluster. However, in the event that a backup is either unavailable or corrupted, you can perform a cluster recovery from a single surviving server node. This node does not have to be the leader.
You will now restart the last healthy node to simulate a cluster recovery from one node. However, this node will not form a cluster by itself. Because the quorum was two nodes at the time of shutdown, the node is currently alone in a cluster. The bootstrap_expect setting does not play a role here, because it is only taken into account for nodes with an empty Consul data directory that are forming a new cluster.
$ ssh $CONSUL_SERVER2 "sudo systemctl start consul" && \
sleep 5 && \
ssh $CONSUL_SERVER2 "consul operator raft list-peers"
Error getting peers: Failed to retrieve raft configuration: Unexpected response code: 500 (No cluster leader)
You can further inspect the node's logs and observe the errors related to currently not having a cluster leader.
$ ssh $CONSUL_SERVER2 "sudo journalctl -u consul -n 10 | grep error | grep leader"
[ERROR] agent.anti_entropy: failed to sync remote state: error="No cluster leader"
[ERROR] agent.http: Request error: method=GET url=/v1/operator/raft/configuration from=127.0.0.1:34078 error="No cluster leader"
Manual recovery using peers.json
This recovery process manually specifies which Consul servers should be a part of the cluster by listing them in a peers.json file that the Consul server agent reads at startup and then immediately deletes.
Place the peers.json file into the raft folder within the Consul data folder. In this case, our servers were configured with the data_dir = "/opt/consul" directive, which means that the absolute path of the file should be /opt/consul/raft/peers.json.
The file structure is a JSON array that contains the node ID, address:port, and voter state of each Consul server in the cluster. To find out the node ID of a Consul server, either scrape the logs for it or inspect the node-id file in the Consul data-dir. You must also note the IP address of the Consul server.
$ ssh $CONSUL_SERVER2 "sudo cat /opt/consul/node-id; echo; hostname -I"
32a6bdd6-29a5-6600-c810-3a7aaec8d239
10.0.4.155
Run the following command to automatically construct a peers.json file that includes consul-server2.
$ tee peers.json > /dev/null << EOF
[
{
"id": "`ssh $CONSUL_SERVER2 'sudo cat /opt/consul/node-id;'`",
"address": "`ssh $CONSUL_SERVER2 'hostname -I | tr -d " "'`:8300",
"non_voter": false
}
]
EOF
The following code block is an example of a populated file with the correct ID and IP address for this specific case. Your values will differ.
peers.json
[
{
"id": "32a6bdd6-29a5-6600-c810-3a7aaec8d239",
"address": "10.0.4.155:8300",
"non_voter": false
}
]
id(string: <required>)- Specifies the node ID of the server. This can be found in the logs when the server starts up if it was auto-generated, and it can also be found inside thenode-idfile in the Consul data directory (/opt/consulin this case).address(string: <required>)- Specifies the IP and port of the server. The port is the server's RPC port used for cluster communications.non_voter(bool: <false>)- This controls whether the server is a non-voter, which is used in some advanced Autopilot configurations. If omitted, it will default to false, which is typical for most clusters.
For the purpose of this tutorial, we consider consul-server0 and consul-server1 a total loss, and you will later redeploy them with an empty state in their Consul data directories. As a result, you cannot include them in a peers.json file. If you try to include them, you will receive the following error in the agent logs.
[INFO] agent.server: found peers.json file, recovering Raft configuration...
[INFO] agent.server: shutting down server
[ERROR] agent: Error starting agent: error="Failed to start Consul server: Failed to start Raft: recovery failed: refused to recover cluster with no initial state, this is probably an operator error"
[INFO] agent: Exit code: code=1
In this case, the only node that was not lost in the simulated outage was consul-server2. Therefore, the peers.json file must only include this node. If you had more than one node that survived an outage situation, you must include all of them in this file.
Have the file ready on your local workstation and populate it with the correct contents for your specific case.
$ touch peers.json
To begin the recovery process, stop the surviving server node. You can attempt a graceful leave, but it is not required.
$ ssh $CONSUL_SERVER2 "sudo systemctl stop consul"
Next, copy the file to the user's home directory on the server nodes.
$ scp peers.json $CONSUL_SERVER2:
peers.json 100% 351 12.6KB/s 00:00
Move the peers.json file to the correct location and set the file permissions. The file was copied under the ownership of the default user ubuntu, and you must change this to consul so that the Consul server agent can read it at startup.
$ ssh $CONSUL_SERVER2 "sudo cp ~/peers.json /opt/consul/raft/ && sudo chown consul:consul -R /opt/consul/raft/"
After you place the peers.json file, start the Consul server agent.
$ ssh $CONSUL_SERVER2 "sudo systemctl start consul"
Inspect the logs to check if the Consul agent has loaded the values from peers.json.
$ ssh $CONSUL_SERVER2 "journalctl -u consul | grep peers.json"
[INFO] agent.server: found peers.json file, recovering Raft configuration...
[INFO] agent.server: deleted peers.json file after successful recovery
Confirm that the Consul server node formed a cluster by itself and is now the leader.
$ ssh $CONSUL_SERVER2 "consul operator raft list-peers"
Node ID Address State Voter RaftProtocol Commit Index Trails Leader By
consul-server2 32a6bdd6-29a5-6600-c810-3a7aaec8d239 10.0.4.155:8300 leader true 3 367 -
New server nodes can now join the cluster to form quorum. Run the following Terraform commands to redeploy the nodes consul-server0 and consul-server1. These two VM instances are redeployed with different IP addresses.
$ terraform taint 'aws_instance.consul-server-group[0]' && \
terraform taint 'aws_instance.consul-server-group[1]' && \
terraform apply \
-target='aws_instance.consul-server-group[0]' \
-target='aws_instance.consul-server-group[1]'
Confirm that the two resources are being recreated and then enter yes.
Resource instance aws_instance.consul-server-group[0] has been marked as tainted.
Resource instance aws_instance.consul-server-group[1] has been marked as tainted.
##...
Plan: 2 to add, 0 to change, 2 to destroy.
##...
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
##...
Apply complete! Resources: 2 added, 0 changed, 2 destroyed.
Reset the environment variables for the node addresses after the new deployment.
$ export CONSUL_SERVER0=ubuntu@$(terraform output -json consul_server_ips | jq -r '.[0]') && \
export CONSUL_SERVER1=ubuntu@$(terraform output -json consul_server_ips | jq -r '.[1]') && \
export CONSUL_SERVER2=ubuntu@$(terraform output -json consul_server_ips | jq -r '.[2]')
Verify that the newly redeployed nodes successfully joined the cluster. You may have to wait for a few minutes while the nodes are provisioned.
$ ssh $CONSUL_SERVER2 "consul members"
Node Address Status Type Build Protocol DC Partition Segment
consul-server0 10.0.4.99:8301 alive server 1.18.1 2 dc1 default <all>
consul-server1 10.0.4.212:8301 alive server 1.18.1 2 dc1 default <all>
consul-server2 10.0.4.155:8301 alive server 1.18.1 2 dc1 default <all>
Now, inspect the status of the Raft peers and verify that the newly redeployed nodes consul-server0 and consul-server1 have inherited the Raft state index from consul-server2 and incremented it by joining the cluster.
$ ssh $CONSUL_SERVER2 "consul operator raft list-peers"
Node ID Address State Voter RaftProtocol Commit Index Trails Leader By
consul-server0 8af019d8-181e-79d3-1dc2-5b4ba577b2de 10.0.4.99:8300 follower true 3 379 0 commits
consul-server1 084dc946-1e11-55be-abb0-332da5e039f5 10.0.4.212:8300 follower true 3 379 -
consul-server2 32a6bdd6-29a5-6600-c810-3a7aaec8d239 10.0.4.155:8300 leader true 3 379 -
All three nodes are part of the cluster and have synced their Raft state. You have successfully restored a cluster from just one surviving node.
Clean up resources
Destroy the infrastructure via Terraform. Confirm the run by entering yes.
$ terraform destroy
##...
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
##...
Destroy complete! Resources: 22 destroyed.
It may take several minutes for Terraform to successfully delete your infrastructure.
Next steps
In this tutorial, you reviewed the process to recover from a Consul server outage. Depending on the quorum size and number of failed servers, the steps involved in the process will vary. However, we recommend that you always have a backup process that you develop and test before an outage. If you experience a total loss of server nodes the method described in this tutorial will not help.
Explore the following tutorials to learn more about Consul disaster recovery: