Self-service application deployment
Nomad Enterprise offers a powerful and flexible platform for self-service application deployment, catering to a wide range of workloads and deployment strategies.
As an individual deploying applications into Nomad, focus primarily on your application's requirements instead of the infrastructure hosting your application. If any of the topics discussed below are not met, establish a clear communication channel with the Nomad platform operators to address these gaps.
Implement a standardized workflow to facilitate a smooth self-service experience This approach eliminates guesswork regarding available resources, networking options, and storage solutions.
It is imperative that you and your team feel equipped to provide a powerful self-service solution for deploying your applications to Nomad in time for the commissioning of production deployments. Use with the topics discussed under Initial Configuration and those below as inputs.
Advanced deployment strategies
Nomad Enterprise offers modern deployment strategies for your long running services that allow for seamless updates, risk mitigation, and minimal downtime. These strategies support both container and non-container workloads.
While rolling upgrades offer an excellent starting point for organizations embarking on their modernization journey, the ultimate goal for many is to implement sophisticated Blue/Green deployment models.
Nomad Enterprise's flexible approach allows teams to evolve their deployment practices gradually, adapting to increasing complexity and operational maturity over time.
Rolling upgrades
Rolling upgrades gradually replace instances of the old version with the new version and if there is an issue during deploying, use auto rollback to minimize service disruption.
Use this strategy for the early stages of Nomad Enterprise adoption as it balances efficiency and risk, making it suitable for many applications, but it can be slower for large deployments and requires careful management of multiple versions during the transition.
Rollbacks are straightforward to execute and crucial for minimizing downtime, however, they do not prevent the initial impact of a deployment. Do not rely upon this for 0% disruption.
To elaborate, if a user has a sticky session with an instance and a rolling update then replaces it, the session may not redirect to the newer instance. Instead, it is terminated.
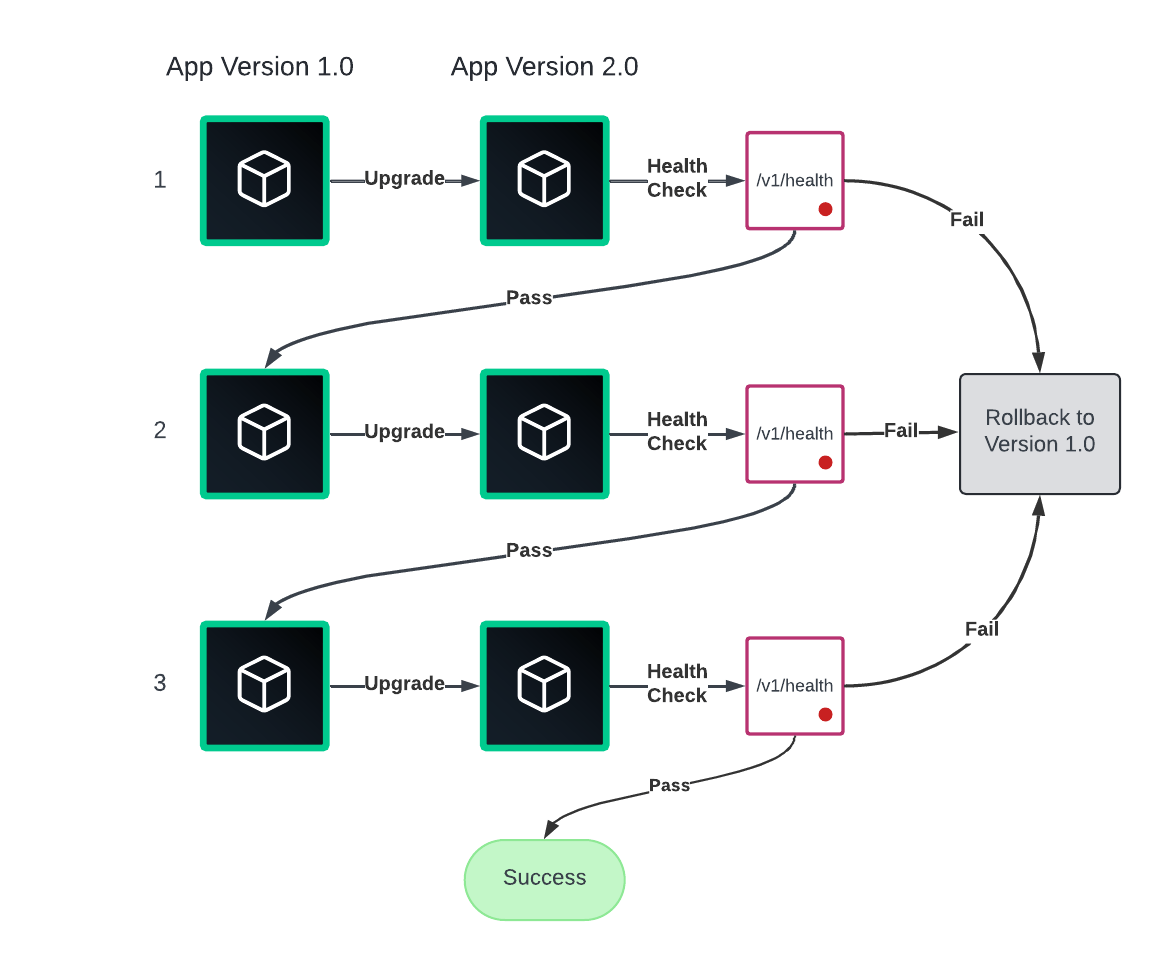
View Rolling updates tutorial for more information on enabling this feature in your jobs.
Recommendations
- View
updatedocumentation for all available options - Set
auto_reverttotrueto revert and rollback to the latest stable job version. - Set your health checks and timeouts correctly for your tasks since the
updateblock uses thechecksblock within a task to ensure a task is healthy before its promoted.
See service discovery section for more details on configuring theservice.checkblock - Use
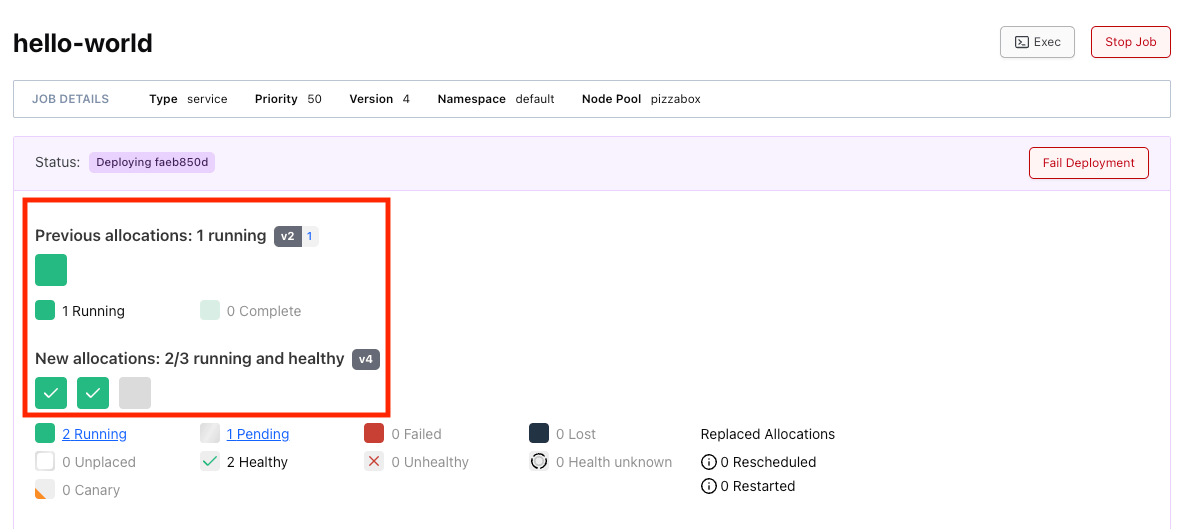
staggerandmax_parallelto ensure a minimal disruption. - You can view the status of the rolling update by view the landing page of your job.
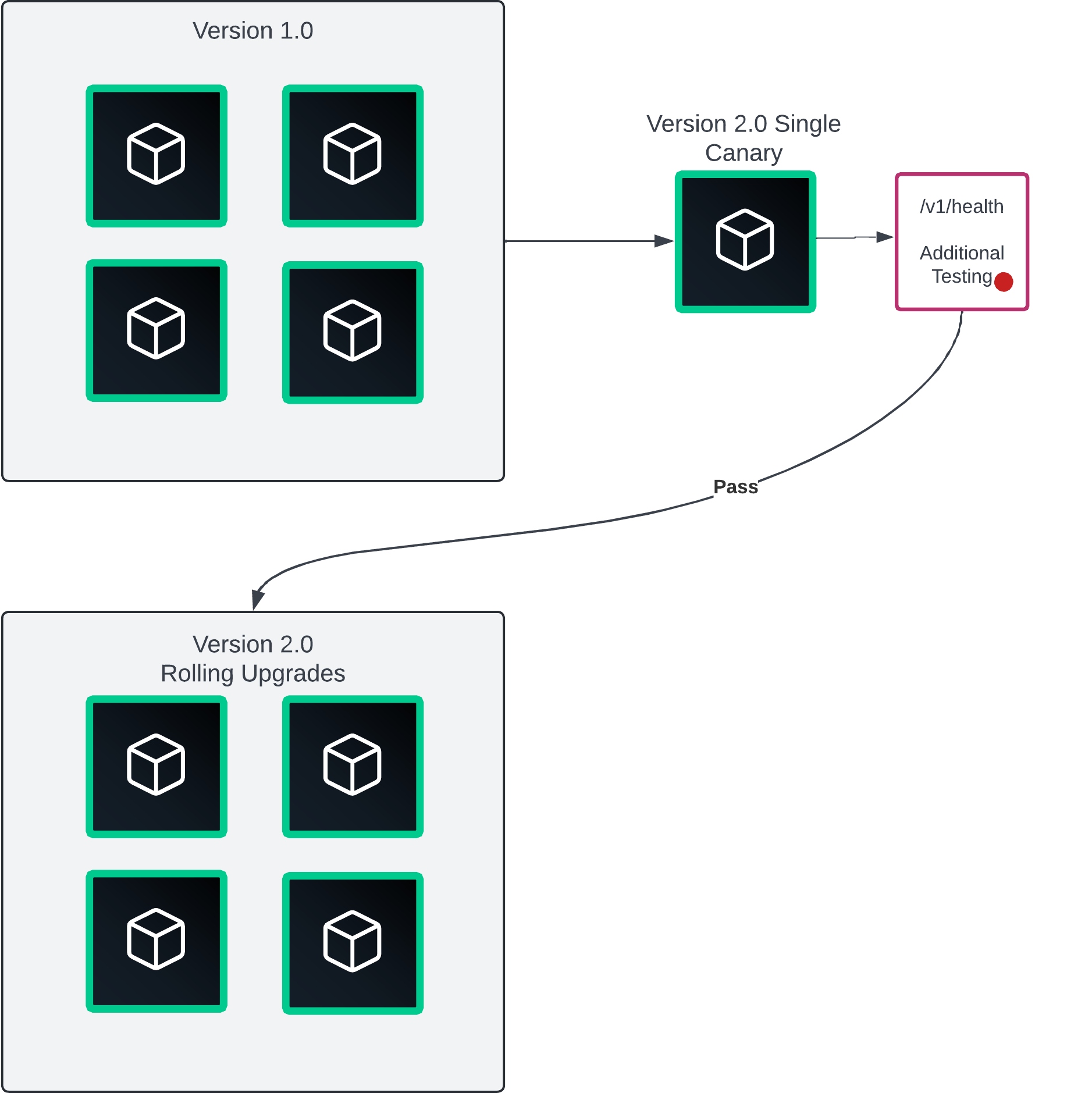
Single canary deployment
Canary deployments involve releasing a new version instance to a small subset of users, without affecting the existing workloads. Accomplish this by using a load balancer or proxy that can dynamically update instances and set various endpoint weights.
Consul Enterprise is a great option by using a service router with service mesh. When you confirm there are no errors, you promote the older instances, by performing a rolling upgrade.
Canary deployments are a great next step after rolling upgrades. Single canary deployments come with the same risks as rolling upgrades along with the small sample size of canary deployments can sometimes lead to misleading performance or usage metrics.
Use this single instance as a production grade test before the final rolling upgrade.
View the Deploy with Canaries tutorial for more information on how to enable this capability for your jobs.
If using Consul Enterprise service mesh, visit Deploy Seamless Canary Deployments with Service Splitters tutorial to learn how to leverage Consul for B/G and Canary deployments.
Recommendations
- Properly evaluate the subset of users who are the best candidates for testing and are swift to report any issues.
- Use Consul or another third party load balancer or proxy to steer traffic during the upgrade.
- Use Manual Promotion if required for tier 1 critical workloads.
- Use automated rollback mechanisms to fail the canary deployment if you receive certain metrics.
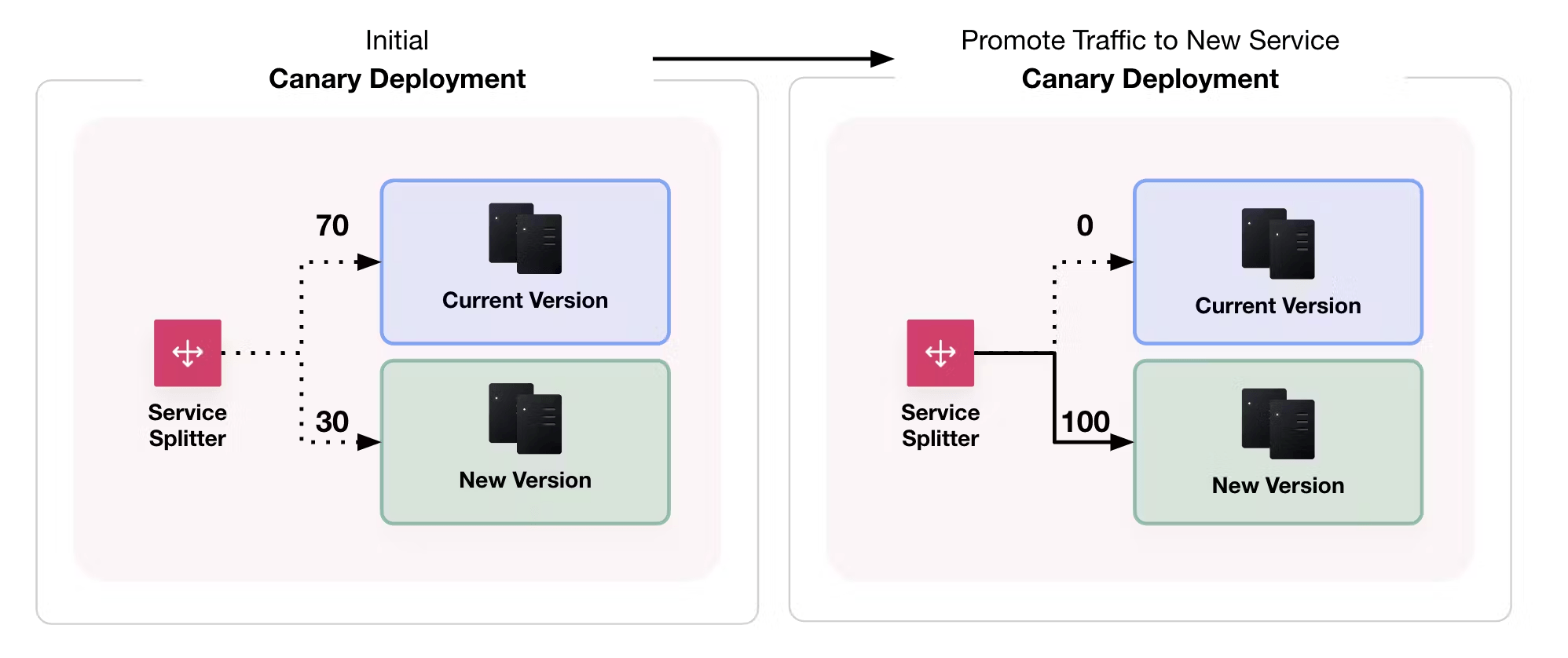
Blue/green deployments
After implementing single canary deployments, Blue/green deployments are the last and best step in your deployment strategy. In a blue/green deployment, there are two application versions.
Only one application version is active at a time, except during the transition phase from one version to the next. The term "active" tends to mean receiving traffic or in service. B/G deployments scale the best and provide zero downtime deployments.
Similar to single canary, accomplish this by using a load balancer or proxy that can dynamically update instances and set various endpoint weights. Consul is a great option by using a service router with service mesh.
When you confirm there are no errors, you cut over traffic incrementally to the newer instances.
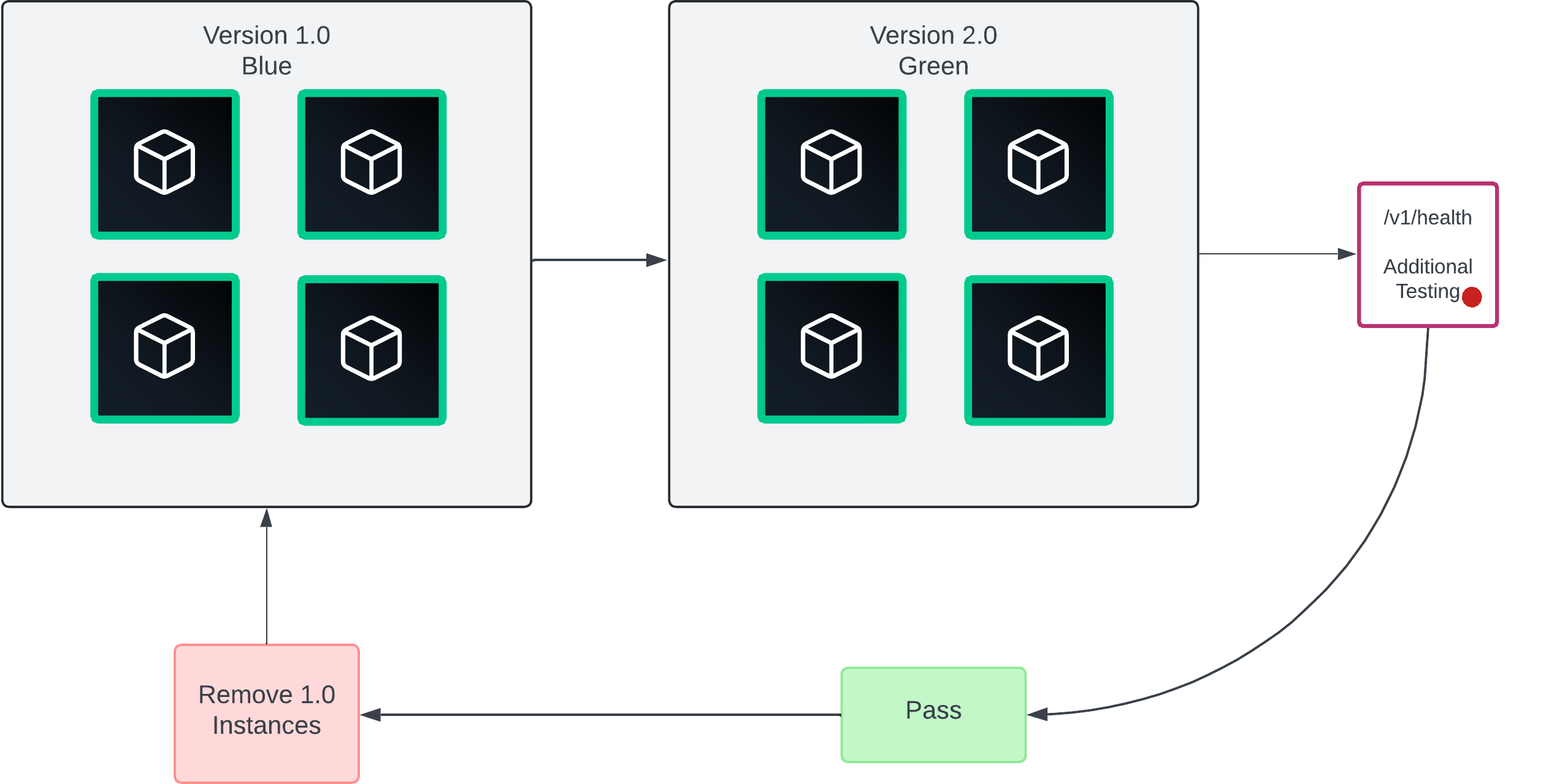
Visit the Blue/Green Deployments tutorial to learn how to implement.
If using Consul Enterprise service mesh, visit Deploy seamless canary deployments with service splitters tutorial to learn how to leverage Consul for B/G and Canary deployments.
Recommendations
- If feasible, consider implementing blue/green deployments at the start of your project.
- Instead of an entire cut-over, consider gradually shifting traffic from blue to green. This strategy helps mitigate risks by limiting the potential impact on the broader user base, allowing for more controlled observation and easier rollback if issues arise.
- Implement automated testing of the new instances before switching users over to the new instances. If your automated testing is sufficient, consider using the auto_promote flag.
- Leverage monitoring and alerting to reveal any issues when new users move over to the new instances.
Workload dependencies
Task dependencies occur when one task relies on another task, job, or external resource to be running or available. There are several patterns to manage these dependencies to ensure your application is dynamic and resilient.
Lifecycle block
Used to express task dependencies in Nomad Enterprise by configuring when a task runs within the lifecycle of a task group. Main tasks are tasks that do not have a lifecycle block.
- Init Tasks - A task that completes and exits before proceeding with the main task
- Sidecar Pattern - A task that starts after the main tasks, but stays alive and runs along side the main task
- Cleanup Task - A task that runs after the main tasks have stopped. They are useful for performing post-processing that is not available in the main tasks.
- Leader Task - use to specify if the task is the leader of the group. If used, all other tasks are dependent on the leader. Meaning, the leader task stops first, followed by non-sidecar and non-poststop tasks, and then sidecar tasks. Once this process completes, Nomad Enterprise triggers post-stop tasks.
Template block
As it relates to task dependencies, templates are useful for generating dynamic configuration data from other workloads such as:
- IP address and/or dynamic ports of a service
- Retrieve KV data from Consul or Vault
- A tasks metadata values
- Retrieve job or client node related variables and use them as environment variables such as the job name, datacenter name, or the bridged network IP address
Use templates to reference another task within the job or you expect data of the upstream job to change. View service discovery section for more information on templating.
Health Checking
The service discovery section details health checking for your services to ensure they are running properly.
However, there are some task dependency specific recommendations:
- Implement a reasonable retry attempt within your application before sending exit signals.
- The built in health checking covers most use cases, however if it is not sufficient, consider implementing circuit breakers within your application code or through Consul service mesh
- You can run multiple health checks for a service. One could check itself, and another could run a script that runs a custom binary command you may use in your environment.
service {
check {
name = "HTTP Check"
type = "http"
port = "api"
path = "/v1/health"
interval = "5s"
timeout = "2s"
}
check {
type = "script"
command = "/bin/bash"
args = ["-c", "/bin/some-binary", "some args"]
}
}
See service discovery health check section for more detailed explanations and recommendations.
External dependencies
When dealing with external dependencies outside of Nomad, you may need to consider several strategies to ensure their applications are resilient and can handle potential issues with these dependencies. Here are some recommendations:
artifactblock The artifact block allows you to download external resources before starting a task. This is useful for fetching configuration files, libraries, or other dependencies. Do not use along side templates, as the artifacts are only retrieved at runtime.
artifact {
source = "https://example.com/app-config.json"
destination = "local/config.json"
}
- Avoid using hard-coded and static data.