Introduction
The purpose of this document is to provide implementation guidance for teams deploying Vault Enterprise on Red Hat OpenShift Container Platform (OCP). It describes platform-aligned patterns, operational considerations, and design decisions for running Vault as a service on OpenShift.
Vault supports multiple deployment models in Kubernetes environments, with a spectrum of client-centric agent and operator solutions intended to streamline secrets management for containerized workloads. In this context, teams may operate the Vault service external to a Kubernetes platform, or deploy it within a cluster, potentially alongside consuming application workloads. This guide focuses specifically on deployments where Vault server runs inside OpenShift as a highly available service, providing secrets management for containerized or traditional applications outside of the immediate cluster.
The content emphasizes architectural choices and day-2 operational practices that are specific to OpenShift, including security controls, storage behavior, networking and routing, lifecycle management, and platform integrations. This content aims to reduce deployment ambiguity and promote consistent, supportable configurations across environments.
Note that while this guide focuses on OpenShift specifically, much of this guidance is also applicable to Kubernetes generally.
Client implementation specifics, application integrations and consumption patterns are not covered in this guide. For detailed information on how to access Vault-managed secrets from your OpenShift-based applications, we recommend reading the following Vault Secrets Operator docs as a starting point:
- Vault Secrets Operator
- Run the Vault Secrets Operator on OpenShift
- Vault Secrets Operator bundle on the Red Hat Ecosystem Catalog
- hashicorp/vault-secrets-operator on GitHub
Platform concepts
This section introduces the core platform concepts that customers need to operate, secure, and support workloads for Vault on Red Hat OpenShift. It frames these concepts from an ownership and operational perspective first, then layers in how they apply when deploying HashiCorp Vault on OpenShift.
Projects
OpenShift organizes workloads around projects, which act as the primary unit of ownership, isolation, and policy enforcement. Platform teams use projects to define clear boundaries between teams, environments, and operational responsibilities.
OpenShift builds on Kubernetes, but it extends the Kubernetes namespace model with additional defaults and controls. A project maps one-to-one with a Kubernetes namespace, while adding opinionated constructs such as role bindings, quotas, and security constraints. These extensions allow teams to encode governance and guardrails centrally rather than relying on each application team to configure them correctly. These features go hand-in-hand with the operational models of HashiCorp Vault.
Platform teams typically provision and manage projects, while application teams consume them. This separation supports consistent access control, predictable resource allocation, and clearer escalation paths when issues arise.
OpenShift runs on major public cloud providers (AWS, Azure, GCP, IBM Cloud) or in on-premises self-managed environments. Regardless of deployment model, the project abstraction remains consistent, which allows administrators to apply the same operational patterns.
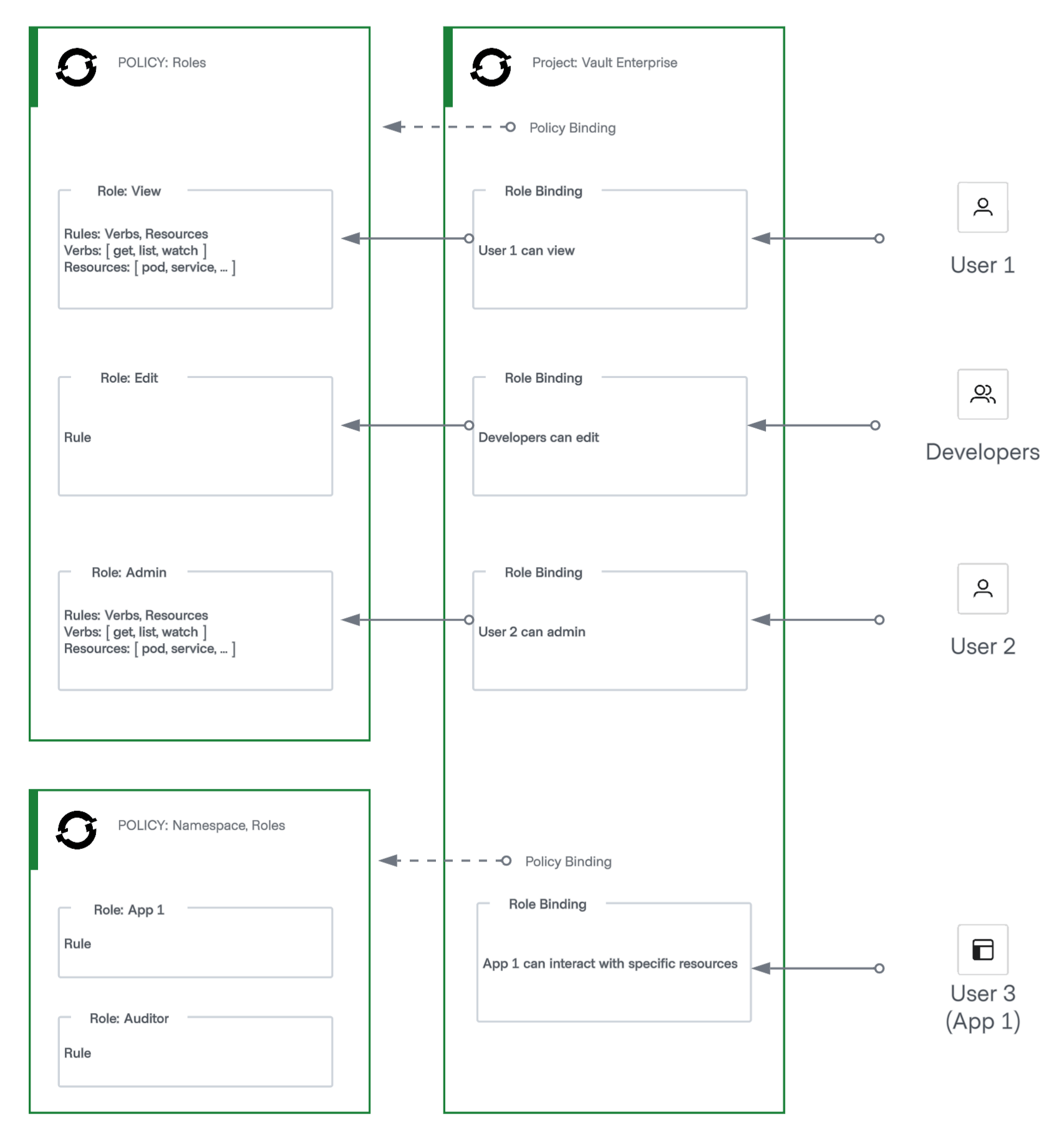
Figure 1. OpenShift core concepts (Projects, Policy roles, policy bindings, users)
Review Red Hat's OpenShift Container Platform Projects to better understand the core platform concepts.