Transform / Transit secrets engines
Overview
In today's digital landscape, protecting sensitive data is paramount. HashiCorp Vault offers two powerful solutions: the Transit engine, which focuses on encrypting and decrypting data without storage; and the Transform engine, which provides format preserving encryption and tokenization for sensitive data. Together, these engines help protect data both in transit and at rest. Implementing these secrets engines helps organizations:
- Enhance Data Security: Centralize encryption and tokenization processes to protect sensitive information.
- Achieve Compliance: Meet regulatory requirements such as PCI-DSS, GDPR, and HIPAA.
- Improve Performance and Scalability: Optimize cryptographic operations for high-throughput environments.
- Simplify Key Management: Streamline key creation, rotation, and destruction.
- Maintain Data Usability: Utilize data transformation techniques that preserve data formats, enabling seamless integration with existing systems.
Common use cases mapped to each encryption engine
Transit engine
- Encryption-as-a-Service: Ideal for encrypting data in transit or at rest without storing the data.
- Use Cases:
- API payload encryption
- Database field encryption
- Securing sensitive configuration data
Transform engine
- Format Preserving Encryption (FPE): Encrypt data while maintaining its original format.
- Tokenization: Replace sensitive data with tokens for secure handling.
- Masking: Obscure parts of data for privacy while retaining usability.
- Use Cases:
- Protecting credit card numbers in retail (PCI-DSS compliance)
- Tokenizing PII for analytics in healthcare (HIPAA compliance)
- Masking data in customer service applications
Prerequisites
Before deploying the Transform engine, ensure that the following prerequisites are met:
- Vault Enterprise Deployment: The Transform engine is a feature of Vault Enterprise and is available with the ADP license.
- Authentication and Authorization Configuration: Proper authentication methods and role-based access controls (RBAC) should be configured to secure access to the Transit and Transform engines.
- Data Classification and Compliance Assessment: Before implementing the Transform engine, conduct a thorough assessment of the data types that require protection and ensure that the configuration aligns with the relevant regulatory compliance requirements, such as GDPR, PCI-DSS, or HIPAA.
Transit engine
Vault’s Transit secrets engine provides cryptographic functions to encrypt, decrypt, sign, and verify data. It is designed to handle high-throughput encryption operations, making it ideal for use cases such as encrypting credit card information during transactions. By simplifying, abstracting, and offloading the encryption process, the Transit engine offers a scalable and secure solution for protecting sensitive data, allowing developers to focus on application logic.
Design considerations
Key Management and Rotation
- Centralized key management: All encryption keys are centrally managed within Vault, providing a single point of control for key creation, rotation, and destruction.
- Automatic key rotation: Configuring Vault to support automatic key rotation ensures that keys are regularly updated without disrupting ongoing operations, enhancing long-term security.
Performance and Scalability
- Optimized for high throughput: The Transit engine is optimized to handle thousands of transactions per second (TPS) with minimal latency, making it ideal for high-volume applications.
- Horizontal scalability: The Transit engine's operations are primarily reads. It does not store data, allowing for high horizontal scalability. Leverage this characteristic by implementing auto-scaling in cloud environments or by adding extra capacity to your infrastructure. This approach ensures that the Transit engine can dynamically adjust to varying loads, maintaining consistent performance as demand changes.
Security
- TLS encryption: All communications between clients and the Transit engine are encrypted using TLS, safeguarding data in transit.
- Access control: Strict access controls are enforced via Vault's policy framework, ensuring only authorized clients can perform operations using the Transit engine.
Encryption Algorithms
- Algorithm diversity: The Transit engine supports a variety of encryption algorithms, including AES-256-GCM (default), ChaCha20-Poly1305, ED25519, and more.
Implementation
Setup and Configuration: For detailed implementation steps, please refer to the official Vault Transit secrets engine tutorial. This guide provides comprehensive, step-by-step instructions for setting up and using the Transit engine.
Key implementation steps include:
- enabling the Transit engine
- creating encryptions keys
- encrypting and decrypting data
- configuring key rotation.
Integration with Applications: Integrate your application to call Vault's Transit API for encrypting credit card information before storing or transmitting data. Ensure your applications can handle the encrypted data formats.
Error-handling and Logging: Implement comprehensive error handling in your integration code to manage scenarios such as network issues, authentication failures, or Vault unavailability. Incorporate retry mechanisms with exponential backoff, and ensure that your application can gracefully handle exceptions without data loss. Enable and configure Vault's audit logging to track all Transit engine operations for security and compliance purposes.
Use cases covered
| Use Case | Summary |
|---|---|
| Encrypting credit card information | In environments where sensitive data protection is crucial - such as retail, banking, or healthcare - it is essential to encrypt customer information. By using Vault's Transit engine, organizations can encrypt credit card data before storing it in a database or transmitting it across networks. This ensures that even if the data is intercepted or accessed without authorization, it remains protected. |
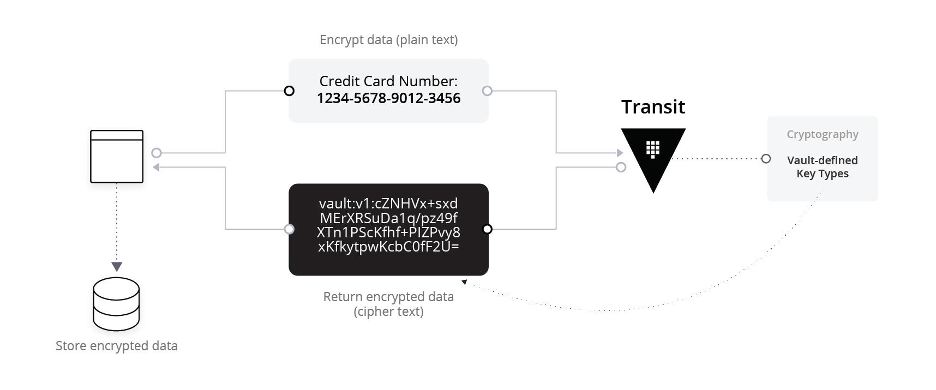
Data flow overview
- Encryption: Before storing or transmitting, the application sends the plaintext credit card number to Vault's Transit engine to receive the cipher text.
- Decryption: When needed, the application sends the cipher text to Vault to retrieve the plaintext.
Best practices
- Use Short-lived Tokens: Implement short-lived tokens when interacting with Vault, including with the Transit engine. This practice significantly reduces the risk of compromise by limiting the lifespan of access credentials. Configure Vault's token policies to set appropriate maximum time-to-live (TTL) values for tokens. Integrating ephemeral tokens into your security framework significantly strengthens the security posture of your Vault deployment. This approach not only fortifies access control mechanisms, but also aligns with industry standards and regulatory requirements, ensuring compliance.
- Regularly Rotate Keys: Implement a key rotation policy that balances security with operational efficiency. Vault's Transit engine supports automatic key rotation, allowing you to schedule rotations at regular intervals or after a specific number of encryption operations. When implementing key rotation:
- Use Vault's key versioning feature to maintain multiple versions of encryption keys. This is managed by Vault admins, not application developers.
- Implement a rolling update strategy for rewrapping cipher text. Periodically rewrap encrypted data to use the latest key version. This can be done as a background process or during regular read operation.
- Design your applications to handle potential temporary unavailability during key rotation operations. Implement retry logic for encryption and decryption operations to handle temporary failures.
- Regularly test your key rotation and rewrapping procedures to verify that they function as expected and that the data remains accessible after a rotation.
Transform engine
Vault's Transform secrets engine is designed to protect sensitive data through mechanisms that preserve data formats, tokenize sensitive information, or apply data masking. This engine is particularly useful in scenarios where maintaining the usability of data — such as length or format — is critical while still ensuring that the data is secure.
The Transform engine ensures data security while preserving data usability through techniques like format preserving encryption (FPE) algorithms such as FF1 and FF3-1, secure tokenization, and customizable data masking.
Its flexibility makes it suitable for various use cases, from tokening personally identifiable information (PII) for compliance to applying FPE in financial services.
By leveraging the Transform engine, organizations can achieve:
- Enhanced data protection while preserving data usability,
- Compliance with various data privacy regulations,
- Improved performance for data transformation operations, and
- Simplified management of data protection processes across different use cases.
Implementation
Enable the Transform Engine: To begin using the Transform engine, it must first be enabled in Vault. This can be done using the following command:
$ vault secrets enable transformOnce enabled, you can configure the engine to meet your specific needs, including setting up transformations, defining role, and managing access controls.
Defining Transformations: Transformations are the core feature of the Transform engine. A transformation can be a process like FPE, tokenization, or data masking when applied to specific types of data.
Use cases covered
| Use Case | Summary |
|---|---|
| FPE for structured data | Encrypting data such as SSNs or credit card numbers while preserving the original format, enabling seamless integration with existing systems that expect data in a specific format. |
| Tokenization for compliance | Replacing sensitive data elements with tokens to ensure compliance with data privacy regulations, while maintaining data usability for business processes. |
| Masking for data privacy | Masking sensitive data fields to prevent unauthorized access while allowing partial visibility for operational use cases, such as displaying the last four digits of a credit card number. |
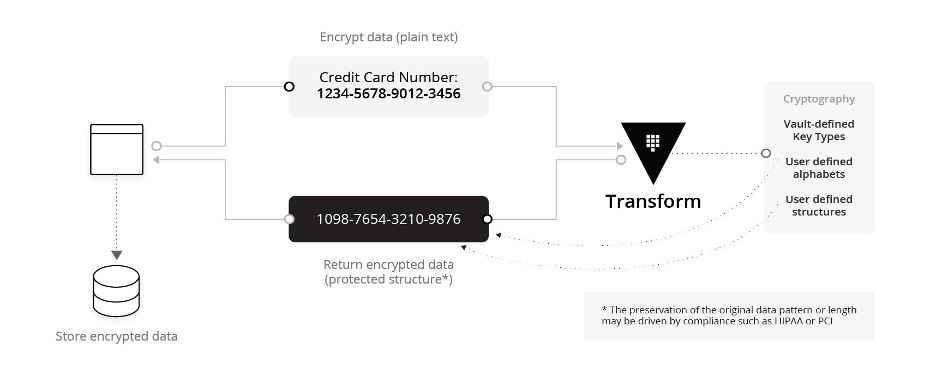
Format preserving encryption
FPE allows you to encrypt data while preserving its original format. For example, a 16-digit credit card number can be encrypted but will still appear as a 16-digit number, which is essential for systems that require specific data formats.
To define a template and an FPE transformation, use the following command:
## Define a template for credit card numbers
$ vault write transform/template/ccn-template \
type=regex \
pattern='(\d{4})-(\d{4})-(\d{4})-(\d{4})' \
alphabet=builtin/numeric
## Create an FPE transform using the template
$ vault write transform/transformation/fpe-ccn \
type=fpe \
template=ccn-template \
tweak_sources=internal \
allowed_roles=payments
In this example, the transformation parameter specifies the FPE method for encrypting credit card numbers, ensuring that the encrypted data retains its original structure.
To perform an FPE encoding of a sample credit card number, use the following command:
$ vault write transform/encode/payments \
transformation=fpe-ccn \
value=1111-2222-3333-4444
Key Value
--- -----
encoded_value 9300-3376-4943-8903
Tokenization
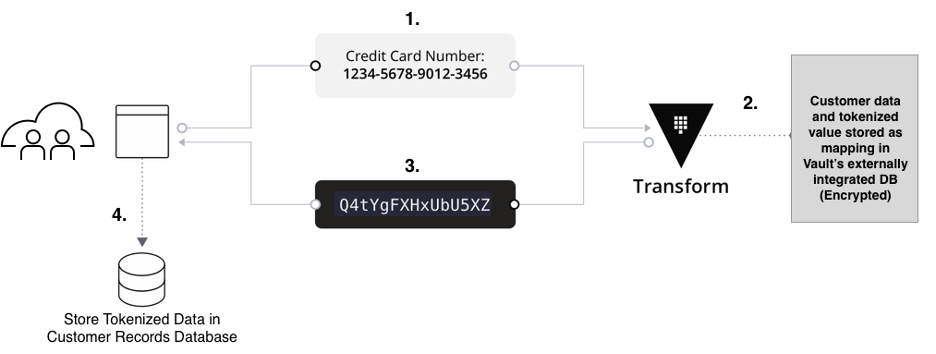
Tokenization replaces sensitive data with a token that has no exploitable meaning outside of Vault. This is particularly useful for securing PII, such as social security numbers (SSNs).
To encode a person's SSN using a tokenization transform, use the following command:
$ vault write transform/encode/payments value="123-45-6789" \
transformation=us-ssn
Key Value
--- -----
encoded_value 233-76-4943
The result is a token that represents the original SSN, but can be safely used without exposing the sensitive data.
Security considerations for tokenization
When implementing tokenization with the Transform engine, it is crucial to address specific security considerations to ensure the protection of sensitive data. Tokenization replaces sensitive data with tokens. If not properly secured, however, it can introduce vulnerabilities.
Key security considerations:
- Token Storage Security: Ensure that the tokenization storage backend - whether using Vault's integrated storage or an external SQL database - is securely configured. Implement strong access controls, encryption at rest, and regular security audits to protect token-to-value mappings from unauthorized access.
- Access Controls: Use Vault's policy framework to enforce strict access controls on tokenization operations. Define clear roles and permissions to ensure that only authorized users or services can perform encoding and decoding operations.
- Data Minimization: Limit the amount of sensitive data processed and stored. Only tokenize data that is necessary for your application's functionality to reduce exposure.
- Audit Logging: Enable Vault's audit logging to monitor all tokenization activities. Regularly review audit logs to detect and respond to any unauthorized access attempts or suspicious activities.
- Compliance Alignment: Ensure that your tokenization implementation aligns with relevant regulatory requirements such as PCI-DSS, GDPR, or HIPAA. Properly securing tokenization processes aids in maintaining compliance and avoiding potential penalties.
For detailed information on security considerations for tokenization, please refer to Security Considerations for Tokenization.
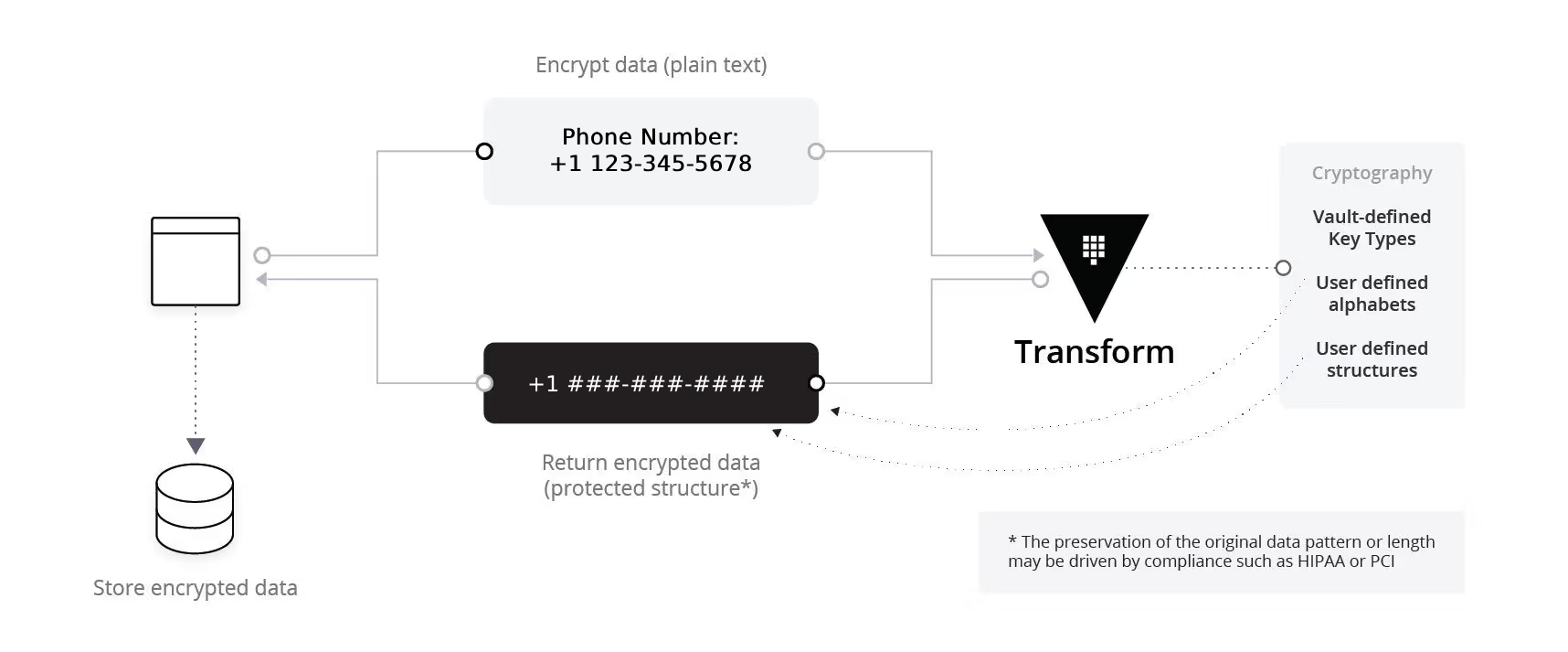
Data Masking
Data masking is used to partially obfuscate data, allowing for limited visibility. It is intended to hide sensitive data from those who do not have a clearance to see them, while retaining data format options for operational purposes. To implement data masking of a phone number, use the following command:
$ vault write transform/encode/payments value="+1 123-345-5678" \
transformation=phone-number
Key Value
--- -----
encoded_value +1 ###-###-####
This will output a masked version of the phone number containing "#" as the masking character as defined in the transformation rule.
Managing roles and access
Roles are essential for controlling who can access and perform operations within the Transform engine. Each role should be tied to specific transformations and operations, ensuring that clients have only the permissions they need.
- Creating a Role: Define roles that specify which transformations users or service can access.
$ vault write transform/role/payments \
transformations=card-number,uk-passport,us-ssn
This role allows access to the card-number, uk-passport, and us-ssn transformations.
- Assigning Permissions: Use Vault policies to assign specific permissions to roles, such as the ability to read, write, or manage transformations.
path "transform/encode/payments" {
capabilities = ["create", "update"]
}
path "transform/decode/payments" {
capabilities = ["create", "update"]
}
Implementation best practices
Integrating the Transform engine effectively with your existing databases and applications is essential for a successful deployment. Start by identifying the applications or services that will interact with the engine for encryption, tokenization, or data masking. Update your application logic to utilize the Transform engine's APIs whenever sensitive data needs processing, ensuring your applications can smoothly handle the transformed data formats.
Implement HTTP connection pooling to optimize performance during Transform operations, This minimizes the overhead of establishing new connections for each API call by reusing HTTP connections, thereby reducing latency from repeated TCP handshakes and SSL/TLS negotiations. Configure the maximum total connections and maximum connections per route to match your application's concurrency needs. Set appropriate connection and socket timeouts to prevent hanging connections. Incorporate error handling strategies for network issues, including retries with backoff mechanisms.
When scaling tokenization, consider configuring external SQL stores to manage tokenization mappings. Set up an external SQL database, such as MySQL, PostgreSQL, or Microsoft SQL Server to store the relationships between plaintext values and their corresponding tokens. Optimize your database performance to handle the frequent read and write operations involved in tokenization. Ensure high availability by implementing replication and clustering for your database, providing fault tolerance and minimizing the risk of disruptions in tokenization services due to database failures.
Performance characteristics
- Optimizing Encryption Operations and Batch Processing: To ensure optimal performance of format preserving encryption (FPE) and other Transform operations in high-volume environments, it is crucial to establish and monitor key performance metrics. Begin by setting baseline response times for individual Transform operations and tracking operations per second. Regularly monitor these baselines for any significant deviations, which could indicate any performance issues. Additionally, monitor CPU utilization across Vault nodes, tracking both average and peak levels. To process large datasets, implement batch processing for bulk Transform operations. This approach can significantly reduce overhead and improve overall throughput compared to processing individual items, making it an effective strategy for handling high volumes of data. Batching is particularly useful in environments where FPE is applied to large datasets, such as batch processing of customer data. Additionally, consider implementing caching strategies to further optimize performance. Caching frequently encrypted values can reduce the load on Vault, especially when the same data requires repeated encryption operations. This is particularly relevant in scenarios where certain data fields, such as SSNs, are encrypted multiple times across different applications.
- High-volume Tokenization Management: Tokenization replaces sensitive data elements with tokens that can be used in place of the original data for business processes. To manage tokenization at scale, ensure that the Transform engine is configured to handle high throughput. This involves optimizing the database backend, if an external SQL database is used to persist the tokens. Regular performance tuning, such as indexing the database and optimizing query execution plans, can significantly enhance the speed and efficiency of tokenization operations. Additionally, use monitoring tools to track the performance of the tokenization engine to adjust as needed for maintaining optimal throughput.
- Latency Reduction: In environments with strict performance requirements, such as real-time processing of financial transactions, minimizing latency is critical. Deploying Vault clusters close to the data sources and clients can reduce the time it takes for tokenization requests to be processed. Implementing load balancers to distribute tokenization requests evenly across multiple Vault nodes also helps in maintaining consistent performance under high load conditions.
Scaling Vault for Transit and Transform operations
As your use of Vault's Transit and Transform engines grows, you may need to scale your deployment to maintain performance and reliability. Vault's horizontal scalability is particularly advantageous for the read-intensive operations common to these engines. This section provides guidance on how to effectively scale your Vault deployment to support growing Transit and Transform workloads, while also benefiting other Vault operations.
Key scaling considerations
- Read-oriented Operations: The Transit engine and most Transform engine operations (excluding tokenization) are primarily read-oriented. This allows these operations to benefit significantly from horizontal scaling. Adding non-voter (performance standby) nodes to your Vault cluster increases capacity to handle Transit and Transform operations, as these nodes can serve read requests without participating in the consensus protocol.
- Tokenization Considerations: Tokenization involved high-frequency write operations to store plaintext-token mappings. This can place substantial load on Vault's storage backend. To optimize performance, use external SQL stores. Configure an external SQL database (such as MySQL, PostgreSQL, or Microsoft SQL server) to store tokenization mappings. This helps offload any write-intensive tokenization tasks from Vault's internal storage to an external database, leveraging the database's ability to handle high write loads efficiently, while allowing Vault to scale its other operations effectively.
Scaling strategy
- Monitor Performance: Regularly track key performance indicators such as CPU utilization, throughput, and latency in your Vault cluster. Establish alerts based on predefined thresholds to proactively scale your deployments before they impact performance.
- Optimize Load Balancing: Configure your load balancers to distribute read traffic efficiently across non-voter nodes. This approach reserves voter nodes for write operations and cluster management tasks, improving overall performance.
- Scale CPU and Memory Resources: Since Transit and Transform operations are CPU-intensive due to cryptographic processing, scaling up CPU resources on Vault nodes can improve throughput and reduce latency. Ensure sufficient memory is available to handle concurrent operations effectively.
- Add Performance Replicas: For additional scaling, consider adding performance replicas. This reduces the load on the primary cluster and improves response times.